

-
�I�շ���
- FPGA����
- MATLAB����
- Simulink����
- ���㷨/�¼��g�A��
Copyright 2017-2025 © ���d�����R��ܛ���_�l������ �Wվ�䰸̖:��ICP��18008591̖-1
�����ֽM̎������(Group Method of Data Handling��GMDH)�������F�����ھ��^�̵��ԽM�����ƣ���һ�����θ�Ч���ƌ��ģ�͵�ԭʼݔ��׃�����_ʽ���㷨�����Կ��^�ķ�ʽ����һ������s��ģ�͡�Ivakhnenko��1967�����GMDH������Ҳ�Q���ʽ�W�j������ǰ���W�j�г��õ�һ�N�����A�y���W�j��GMDH�����Ļ���˼�����������ЙC�w�ݻ��ķ������씵�Wģ�͡���ϵ�y��ݔ���Ԫ����M�Ϯa��һϵ�еĻ����Ԫ������ÿһ��Ԫ�������x������f�����Ĺ��ܣ��ُ��Ѯa����һ����Ԫ�x�������cĿ��׃�����ӽ�����Ԫ�����x������Ԫ�����Y���ٴήa���µ���Ԫ���؏��@��һ�������z��������������M�����^�̣�ֱ���®a����һ����Ԫ��������һ�����Ӄ��㣬�����ģ�ͱ��x�����������c�ǾW�j�Y�����̶���������Ӗ�����^���в���ظ�׃������һ���w�{����������Ч�Ľ�Q���T��ͨ���W�j�\�Еr�g�L�W���ٶ�����С�����ӱ��������^��r�Ķ��ع����ԵȆ��}��
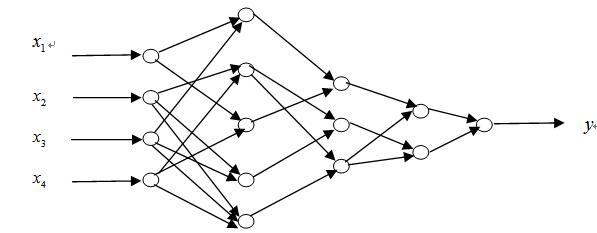
1.3 ����GMDH�W�j���A�y
��GMDH�W�j�M���A�yǰ������Ҫ�˽�r�g���е�һЩ�������H�H������֪�ӱ���ͨ�^�W�j�ԽM������ʽ�����W�jģ�͡�GMDH�W�j�Ę����^����Ҫ��һ������a�������Ԫ�����ⲿ�ʄt����Ԫ�M�кY�x���Y�x�õ�����Ԫ�ٽY�Ϯa����һ����Ԫ��ֱ��������я��s�Ե�ģ�ͱ��x�����@��һ���^�̡�GMDHģ�͵Ľ�����Ҫ���ׂ����E��
��1�� �����A̎������������Ҏ�����ͳ�ȥ�����е��oֱֹ���ɷ֡�
��2�� �Q���W�jݔ����̖�������A�y��Ҫ�õ�n���^ȥݔ��ֵ��
��3�� �������֞�Ӗ���ӱ��͜yԇ�ӱ���
��4�� ����ݔ����Ԫ�ӡ���Ԫ���cݔ����̖��i���P������ÿ��ݔ����̖������һ����Ԫ�c֮�����������������Ԫ������
��5�� ����Ԫ��ֵ�ij�ʼֵ�O��0.
��6�� ��Ӗ�������M������ݔ��ӵ�ÿһ����Ԫ����k�r��ȡ![]() ��k=1��2����������ݔ����̖��
��k=1��2����������ݔ����̖��![]() ������ݔ����Ӌ��ÿһ��Ԫ��ݔ���`����������ֵ�;����`��ͣ��������`��ʹ�����һѭ�hӋ��ֵ�r��Ӗ��ֹͣ��
������ݔ����Ӌ��ÿһ��Ԫ��ݔ���`����������ֵ�;����`��ͣ��������`��ʹ�����һѭ�hӋ��ֵ�r��Ӗ��ֹͣ��
��7�� ݔ���x����Ӌ��ÿһ��Ԫ��ݔ�������������ֵ�_��һ���ֵ���x��С���ֵ����Ԫ������һ����Ԫ��
��8�� ��������С���������ǰһ����Ԫ����С������ӃH��һ����Ԫ�r��ֹͣӖ���^�̡����Ӗ����������С������ƫ���ֹͣ�ģ��t��ǰһ����Ԫ����ݔ���ӣ������������W�j����Ӗ�����ӃH��һ����Ԫ��ֹͣ�ģ��ұ��η���С��ǰһ�ӕr���t�Ա�����Ԫ����ݔ���Ӳ����������W�j�����ᗉ��Щ�cݔ����Ԫ�]��ϵ����Ԫ��
��9�� �����u�r�����M�z��Ӗ���õľW�j���ܡ��u�r�����M�����������ӱ������͜yԇ�����ĽY�ϣ�Ҳ������һ�Mȫ�µĔ������Ķ����F�A�y���ܡ�
1.4 GMDH�ڵ���ˮλ�A�y�еđ���
��B55�ĵ���ˮλ�����������Ȍ�ԭʼ�������wһ��̎����Ȼ��������ݔ����̖���ٌ�������ǰ132����Ӗ���ӱ��������W�j����100��������yԇ�ӱ����z�W�j���ܡ����g��Ӌ���^����MATLAB7.1ƽ�_�ό��F��
ϵ��highspeedlogic
QQ ��1224848052
�ţ�HuangL1121
�]�䣺1224848052@qq.com
�Wվ��http://www.mat7lab.com/
�Wվ��http://www.hslogic.com/
�Œ�һ�ߣ�
