�C���W(xu��)��(x��)�бO(ji��n)���W(xu��)��(x��)���o�O(ji��n)���W(xu��)��(x��)����O(ji��n)���W(xu��)��(x��)�����ӌW(xu��)��(x��)�������W(xu��)��(x��)�@5�N�W(xu��)��(x��)��ʽ��������(j��)���W(xu��)֪�R����ģ�ͣ��Y(ji��)��(g��u)��ͬ������ʹ���T����(j��ng)�W(w��ng)�j(lu��)���Q�ߘ䡢Ҏ(gu��)�t��ؐ�~˹�W(w��ng)�j(lu��)�ȷ���ȥ��(g��u)���W(xu��)��(x��)�㷨����ȌW(xu��)��(x��)Ŀǰ�����f��һ�N������(j��ng)�W(w��ng)�j(lu��)�ČW(xu��)��(x��)��������Ŀǰ�˹������@ô�𱬣��ܴ�̶��Ϛw������ȌW(xu��)��(x��)�șC���W(xu��)��(x��)�㷨�ijɹ���(y��ng)�ã��簢����������ɭ�����g�C����Ę�R�e���o��܇�ȡ���ƪ������ȌW(xu��)��(x��)��

���W(xu��)��(x��)���z�֣��������˂����ܵ��C��������ˮƽ�ˡ��ټ��ϡ���ȡ��z�֣�ԭ�������X�@�M�˟o߅�o�H����������������Ρ��@�ɾ�Ԓ��ֻ�Ǟ��˱����Ҍ���ȌW(xu��)��(x��)�@�����ֵđB(t��i)�ȣ���̫�����ˣ�
��ȌW(xu��)��(x��)��Ŀ�ģ���Ҫ�õ��ӱ���(sh��)��(j��)��ݔ��ݔ����(sh��)��(j��)֮�g���P(gu��n)ϵ���@���P(gu��n)ϵ���H����һ������(sh��)���ڌ��H�����г��á�ģ�͡��z�ց���ʾ�@������(sh��)����ʲô�����һ���˲�֪������(sh��)������(sh��)���Д�(sh��)�W(xu��)���x�ģ���һ����Ҳ��֪��ģ�ͣ�����ģ�Ϳ����� ��ȥ�ƶ��Ƕ������������Ƶ�ͬ־���f��������(sh��)���z�ֱ��_�ĸ����һЩ�����H�У���ȌW(xu��)��(x��)���Á�W(xu��)��(x��)��θ���(j��)�ɼ��Ĕ�(sh��)��(j��)���R�eijһ�����w�����@��������(sh��)����һ���̶��Ͼͱ������@�����w�����ԣ���˴��Ҳ�ͳ����á�ģ�͡��z�ց�������ȌW(xu��)��(x��)�õ��ĺ���(sh��)�P(gu��n)ϵ��ģ�ͣ������˃ɌӺ��x��һ���fģ�͌��H����һ������(sh��)�P(gu��n)ϵ�������f�@������(sh��)���Á��������w���Եġ�
��ȌW(xu��)��(x��)����������һ�N�����ĺ���(sh��)�M�Ϸ���
�м�����һ���҂����ЌW(xu��)�^�ľ��Իؚw���̣����O(sh��)�҂��õ���һ�M�P(gu��n)��ʩ��������ˮ���a(ch��n)���Ĕ�(sh��)��(j��)��
|
ʩ������
|
15
|
20
|
25
|
30
|
35
|
40
|
45
|
|
ˮ���a(ch��n)��
|
330
|
345
|
365
|
405
|
445
|
450
|
455
|
�@�M��(sh��)��(j��)�L�Ƴɶ��Sƽ��D֮����һϵ�е�ɢ�c�����ǣ��҂�����ʹ��һ�lֱ��ȥ�M��ʩ��������ˮ���a(ch��n)��֮�g���P(gu��n)ϵ��ͨ�����f��ֱ�����̿��Ա�ʾ��y=ax+b���ڱ����У�y��ָˮ���a(ch��n)����x��ָʩ����������a��b�ɂ�����(sh��)�Á�����ʩ��������ˮ���a(ch��n)��֮�g�Ĕ�(sh��)�W(xu��)�P(gu��n)ϵ��
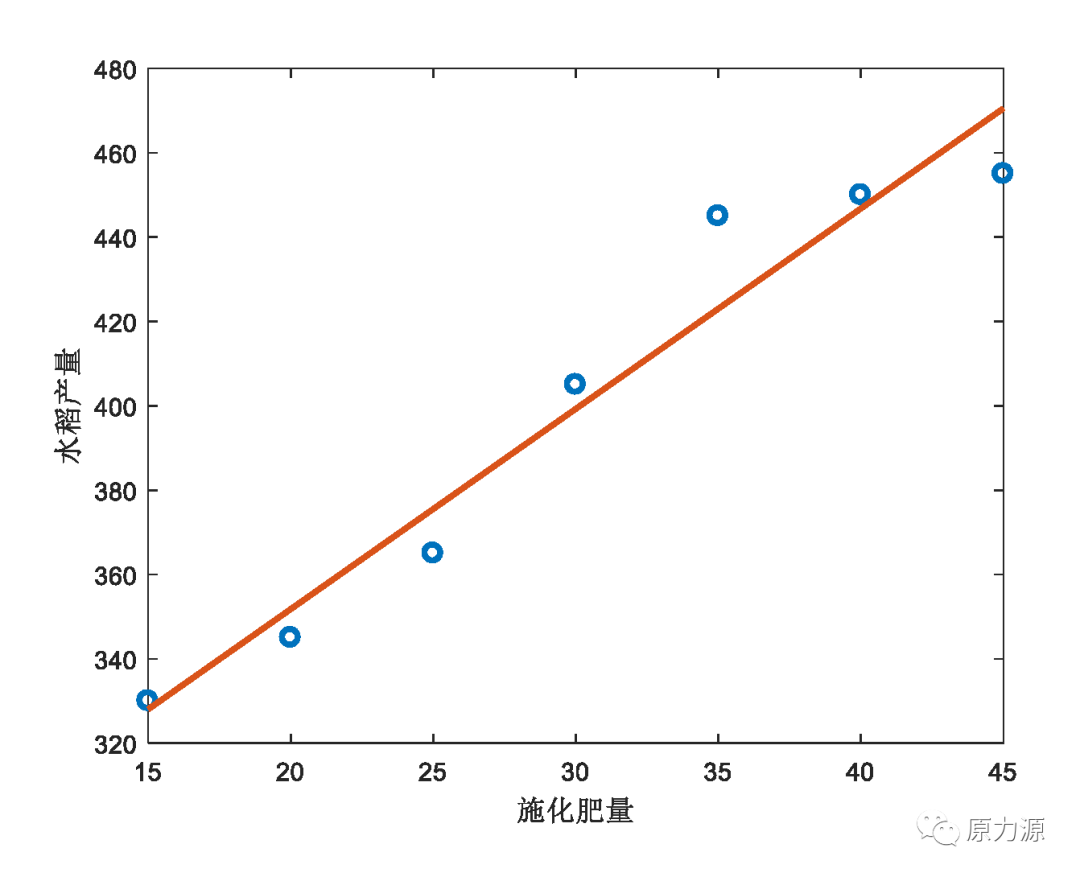
���愂���v������ȌW(xu��)��(x��)��K��Ŀ���ǵõ�һ��ģ�́������ӱ���(sh��)��(j��)��������ϵ�y(t��ng)���Dz��Ǹ��X�����Իؚw���}�����ƣ�
�ڌ��H�����У��҂����о�������ܱ��^��(f��)�s�����y��һ�����Է��́���ʾ��ģ�͡�ֵ�ø��d���ǣ��о����ѽ�(j��ng)�C����һ��������(j��ng)�W(w��ng)�j(lu��)�����Á������κ���ʽ�ĺ���(sh��)����ˣ���ȌW(xu��)��(x��)ͨ��ʹ����(j��ng)�W(w��ng)�j(lu��)�������о������ģ�͡�
������(j��ng)�W(w��ng)�j(lu��)����ȌW(xu��)��(x��)Ҫ���ľ���ʹ�����еĘӱ���(sh��)��(j��)�����ú��m�ă�(y��u)��������ȥ�����܉���õ������о��������Ե���(j��ng)�W(w��ng)�j(lu��)����(sh��)��һ���õ����(y��u)�ą���(sh��)����(j��ng)�W(w��ng)�j(lu��)�Ϳ��Զ��ͣ��҂��Ϳ����ڌ��H��(y��ng)����ʹ���@���Ѷ��͵���(j��ng)�W(w��ng)�j(lu��)���Д�ɼ��Ĕ�(sh��)��(j��)�Ƿ�����҂����о�����(d��ng)Ȼ���c���Իؚw��ȣ���ȌW(xu��)��(x��)���^�̷dz���(f��)�s��
�˹���(j��ng)�W(w��ng)�j(lu��)����������(sh��)�����r����(sh��)���ݶ��½����������������W(xu��)��(x��)�Ďׂ��P(gu��n)�I�c
�˹���(j��ng)�W(w��ng)�j(lu��)����ȌW(xu��)��(x��)�Ļ��A(ch��)����ȌW(xu��)��(x��)�ĽY(ji��)��ͨ��������(j��ng)�W(w��ng)�j(lu��)����ʽ��ʾ�ġ��c�˵Ĵ��X��(j��ng)�W(w��ng)�j(lu��)��ƣ��˹���(j��ng)�W(w��ng)�j(lu��)�Ļ��A(ch��)���˹���(j��ng)Ԫ������(j��ng)Ԫ�ܺ��Σ����Ƿdz�������(j��ng)Ԫ��(li��n)��(li��n)�M����һ��֮�͕���׃�����|(zh��)׃������һ�N��(f��)�s��(j��ng)�W(w��ng)�j(lu��)��
�����(sh��)����(j��ng)�W(w��ng)�j(lu��)��ÿ����(j��ng)Ԫ��ݔ��ݔ������(sh��)������������ȌW(xu��)��(x��)�õ��(y��u)��(j��ng)�W(w��ng)�j(lu��)����(sh��)�������(sh��)������B�m(x��)�ġ�
���r����(sh��)��ָ�o��ݔ�딵(sh��)��(j��)����(j��ng)�W(w��ng)�j(lu��)��ݔ���c�ӱ���(sh��)��(j��)���挍��ݔ����(sh��)��(j��)ƫ�ͨ���õ��ǚ���ƽ���́���ʾ��Ҳ�������ı�ʾ��������̎������
�ݶ��½�������һ�N��Ҋ��ԭ�����^���εă�(y��u)������㷨����ȌW(xu��)��(x��)�^���У��㷨Ҳ�����ô��r����(sh��)��׃����Ӌ���ݶȣ�׃���ʣ������t׃��ؓ�t׃С�����҂���Ŀ�Į�(d��ng)Ȼ�����r����(sh��)Խ��ԽС��Ҳ�������ݶ�һֱ��ؓ���@�����ݶ��½�����˼��
������������Կ�����һ�N����Ӌ����(j��ng)�W(w��ng)�j(lu��)���r����(sh��)���W(w��ng)�j(lu��)����(sh��)�ݶȵķ�����������(j��ng)�W(w��ng)�j(lu��)�Y(ji��)��(g��u)�ď�(f��)�s�ԣ��҂��]����һ��ķ���ȥӋ�����ݶȣ�������������ṩ��һ�N���еķ�����֮���Խз���������������������һ�N�ľW(w��ng)�j(lu��)�����һ���_ʼӋ���ݶȣ�����ǰ��һ�����M����˶�������
��(j��ng)�W(w��ng)�j(lu��)�Y(ji��)��(g��u)��ͬ�a(ch��n)����ͬ����ȌW(xu��)��(x��)����
��ͬ����(j��ng)�W(w��ng)�j(lu��)�Y(ji��)��(g��u)�����a(ch��n)�����õ���ȌW(xu��)��(x��)���������������˼·��ͬС������Ҋ����(j��ng)�W(w��ng)�j(lu��)�Y(ji��)��(g��u)�У����Ӹ�֪�C��DNN�����(j��ng)�W(w��ng)�j(lu��)��CNN���e��(j��ng)�W(w��ng)�j(lu��)��RNN�f�w��(j��ng)�W(w��ng)�j(lu��)�ȡ����Dz���ʹ��ʲô�ӵľW(w��ng)�j(lu��)�Y(ji��)��(g��u)����(j��ng)�W(w��ng)�j(lu��)��K���Á�����ģ�ͺ���(sh��)�ģ��W(xu��)��(x��)���^�̶���ͨ�^�{(di��o)����(sh��)�^��ݔ�����õ��(y��u)����(sh��)�ġ�
һ��Ԓ���Y(ji��)����ȌW(xu��)��(x��)����������һ�N�����ĺ���(sh��)�M�Ϸ������˹���(j��ng)�W(w��ng)�j(lu��)����������(sh��)�����r����(sh��)���ݶ��½��������������ȌW(xu��)��(x��)�Ďׂ��P(gu��n)�I�c����Ҋ����ȌW(xu��)��(x��)��(j��ng)�W(w��ng)�j(lu��)�Y(ji��)��(g��u)�����Ӹ�֪�C��DNN��CNN��RNN����
(li��n)ϵ��highspeedlogic
QQ ��1224848052
�ţ�HuangL1121
�]�䣺1224848052@qq.com
�W(w��ng)վ��http://www.mat7lab.com/
�W(w��ng)վ��http://www.hslogic.com/
�Œ�һ�ߣ�


