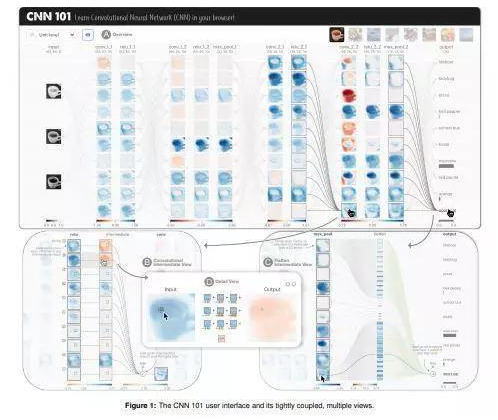
CNN 101: ���e��(j��ng)�W(w��ng)�j(lu��)�Ľ���ʽҕ�X(ju��)�W(xu��)��(x��)
���ˑ�(y��ng)��(du��)��ȌW(xu��)��(x��)ģ���еď�(f��)�s������(zh��n)���о��ˆT�_(k��i)�l(f��)��CNN 101�����@��һ��(g��)����ʽ�Ŀ�ҕ��ϵ�y(t��ng)������Ԏ����W(xu��)�����õ��˽�͌W(xu��)��(x��)���e��(j��ng)�W(w��ng)�j(lu��)�����ǻ��A(ch��)����ȌW(xu��)��(x��)ģ���wϵ�Y(ji��)��(g��u)����
ʹ�ìF(xi��n)��Web���g(sh��)��(g��u)����CNN 101�o(w��)�茣(zhu��n)��Ӳ���������Ñ�(h��)��Web�g�[���б����\(y��n)�����ͨ�^(gu��)�o�ܼ��ɵĽ���ʽҕ�D��CNN 101ͨ�^(gu��)��ጆ���(j��ng)Ԫ��(j��)�e�Լ��Ӽ�(j��)�e�ľ��e��������ͳػ���������ṩ��ģ������ʽ�ĸ�����Ԕ��(x��)�f(shu��)����
CNN 101�M(j��n)һ���U(ku��)���˹�����(du��)��ȌW(xu��)��(x��)���g(sh��)�Ľ���;����������(y��ng)���˽���ʽ��ҕ�����g(sh��)������Ñ�(h��)�ṩ��һ�N����(ji��n)�εķ�����(l��i)�W(xu��)��(x��)��ȌW(xu��)��(x��)�C(j��)�Ʋ�������(j��ng)�W(w��ng)�j(lu��)ֱ�X(ju��)��������������(du��)�ڬF(xi��n)�е�ͨ�^(gu��)����ʽ��ҕ����(l��i)��ጏ�(f��)�s�C(j��)���W(xu��)��(x��)�㷨���о����������CNN 101�����c�����Y(ji��)����һ������
����߀Ӌ(j��)���U(ku��)չCNN 101�Ĺ��ܣ��Á�(l��i)�M(j��n)һ��֧���Ñ�(h��)�Զ��x�͂�(g��)�Ի��ČW(xu��)��(x��)������߀�����ڌ�CNN 101������_(k��i)Դ���(l��i)����TensorFlow Playground��GAN Lab��ƽ�_(t��i)���������Ա��(l��i)��������صČW(xu��)��(x��)�߶������p���L(f��ng)��(w��n)�������
CNN 101 ��ʾҕ�l��
https://www.youtube.com/watch?v=g082-zitM7s&feature=youtu.be
ԭ�ģ�
https://arxiv.org/abs/2001.02004v1
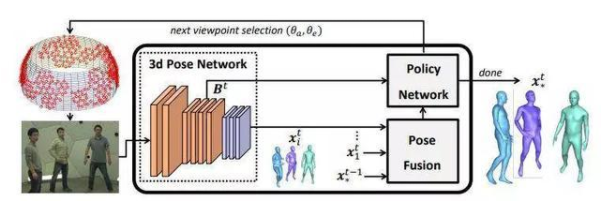
����(d��ng)���w�˄�(sh��)��Ӌ(j��)����ȏ�(qi��ng)���W(xu��)��(x��)
�˄�(sh��)��ȏ�(qi��ng)���W(xu��)��(x��)��Pose-DRL����һ�N���ܼ��zӰ�C(j��)���\(y��n)�е�������������ȫ��Ӗ(x��n)������ȏ�(qi��ng)���W(xu��)��(x��)��DRL��������(d��ng)ʽ�˄�(sh��)��Ӌ(j��)�ܘ�(g��u)��ԓ�ܘ�(g��u)�����x���m��(d��ng)?sh��)�ҕ�c(di��n)���ṩ���A(ch��)�Ć����˄�(sh��)�A(y��)�y(c��)������
�о��ˆTʹ�Æ�Ŀ��(bi��o)��Ӌ(j��)���Ͷ�Ŀ��(bi��o)��Ӌ(j��)����(du��)ģ���M(j��n)���u(p��ng)�������ڃɷN��r�¾��@�������õĽY(ji��)�����ԓϵ�y(t��ng)߀�W(xu��)��(x��)�˕r(sh��)�g�Ԅ�(d��ng)ֹͣ�������������Լ���ҕ�l�е���һ�r(sh��)�g̎�����E�^(gu��)�ɵĹ��ܡ�
�о��ˆT�Q(ch��ng)������ʹ��Panoptic��ҕ�D�O(sh��)���M(j��n)�еďV����(sh��)�(y��n)����������(du��)�ڰ�������(g��)�˵ď�(f��)�s��(ch��ng)������҂��C����ԓģ�͌W(xu��)��(hu��)���x���c��(qi��ng)��ҕ�D����(xi��n)������@����(zh��n)�_���˄�(sh��)��Ӌ(j��)��ҕ�c(di��n)����������
ԓϵ�y(t��ng)�W(xu��)��(x��)�x��ҕ�D��������c��(qi��ng)��ҕ�D����(xi��n)��������a(ch��n)�����ˑB(t��i)��Ӌ(j��)����(zh��n)�_����Y(ji��)�����H�@ʾ������ҕ�c(di��n)�x��ă�(y��u)��(sh��)�������߀�C���ˡ��ټ��Ƕࡱ���ں�̫����ܲ����_��ҕ�c(di��n)��Ӌ(j��)������(hu��)��(d��o)�½Y(ji��)��׃������
��x���ࣺ
https://arxiv.org/abs/2001.02024v1
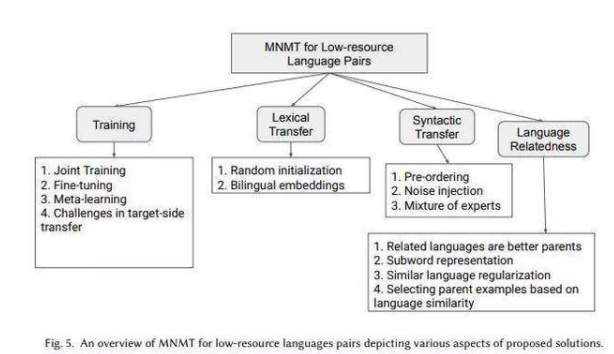
���Z(y��)����(j��ng)�C(j��)�����g�ľC���о�
�ڱ�������������ձ������W(xu��)���ձ���(gu��)����Ϣ�cͨ�ż��g(sh��)�о������Լ�ӡ�ȵ�ܛ�˹������о�Ժ���о��ˆT��(du��)�F(xi��n)�еĶ��Z(y��)����(j��ng)�C(j��)�����g��MNMT���īI(xi��n)�M(j��n)���������{(di��o)�飬����ʹ�о��ˆT�͏ĘI(y��)�ˆT��(du��)MNMTǰ���и�������˽��������
��������(j��)����ʹ�Ì�(sh��)����(du��)MNMT�еĸ��N���g(sh��)�M(j��n)���˺�(ji��n)�η��(l��i)�������������(j��)�YԴ��(ch��ng)���������A(ch��)��ģԭ�������Ć�(w��n)�}������(zh��n)��(du��)�����M(j��n)�� �M(j��n)һ�����(l��i)�����������߀�M���ܵ�ͨ�^(gu��)����^��(l��i)��Q�N���g(sh��)�ă�(y��u)ȱ�c(di��n)����ӑՓMNMT��δ��(l��i)�l(f��)չ����
MNMT���^(gu��)ȥ�������ѽ�(j��ng)����������M��������(l��i)���S��������^���M(j��n)��������������S����Ȥ�ķ���ɹ��M(j��n)һ��̽��������
���ȣ��@�(xi��ng)�������w���c���Z(y��)��NMT����Ҫ��(ch��ng)�����P(gu��n)���īI(xi��n)�������������·������YԴ�����YԴ���D(zhu��n)�ƌW(xu��)��(x��)����(sh��)��(j��)ҕ�����R�^�������Ͷ�Դ���g���������ϵ�y(t��ng)�R������Ҫ���O(sh��)Ӌ(j��)��������׃�w����Ҫ��MNMT��(w��n)�}���佨�h�Ľ�Q�������
��(du��)��NMT�ij��W(xu��)�ߺ͌�(zhu��n)�Ҷ����������@�dz������M(j��n)�ͼ���M(f��i)NMT�о��~������Ҫһ����������κΌ�(du��)��MNMT���dȤ���ˣ��������Դ��������c(di��n)����˼��ā�(l��i)Դ�������
ԭ�ģ�
https://arxiv.org/abs/2001.01115v2
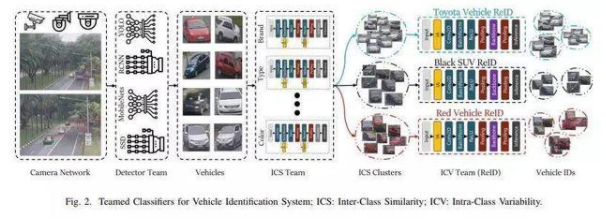
��(qi��ng)���ҿɔU(ku��)չ�Ŀ��ٷ��(l��i)��������܇(ch��)�v��ۙ��܇(ch��)�v���R(sh��)�e
���ڵ�һ�(xi��ng)�о������һ��(g��)ᘌ�(du��)��ͬ�l���z��C(j��)�W(w��ng)�j(lu��)��ҕ�l�����ąf(xi��)�����(l��i)���������@Щ�l��������߶ȡ���ֱ��ʔz��C(j��)�Բ�ͬ���ړ���ģ���ͷ��@�h(hu��n)��������@һ��ܵ��о��ˆT��(l��i)��������(gu��)���������W(xu��)Ժ�Ͱ���ʥ���_��W(xu��)������������һ�N����܇(ch��)�v��ۙ��܇(ch��)�v���R(sh��)�e�Č�(sh��)�F(xi��n)��ʽ������?c��)����Ќ?sh��)ʩ���㏗�W(xu��)��(x��)��ZSL��ϵ�y(t��ng)��(l��i)��(du��)܇(ch��)�v��(zh��)���Ԅ�(d��ng)����ۙ�������
��(du��)VeRi-776��Cars196���u(p��ng)���������ɽM�ķ��(l��i)����ܾ��Џ�(qi��ng)��Č�(du��)������������ԔU(ku��)չ������׃����ҕ�l�����������µ�܇(ch��)�v�(l��i)�� / Ʒ�ƺ��µĔz���^�������ң������c��(d��ng)ǰ���x��(xi��n)ҕ�l����������ȸ����Ќ�(sh��)�r(sh��)����������
�@�(xi��ng)�о������һ�N����܇(ch��)�v��ۙ��ȫ�¼��g(sh��)���������ͬ�r(sh��)Ҳ���M(j��n)�ж˵��˵�܇(ch��)�v������ȡ��܇(ch��)�v�R(sh��)�e������(ji��n)�ζ���(qi��ng)��Ļ��A(ch��)ģ���c��(d��ng)ǰ�����¼��g(sh��)��Ⱦ���һ����(j��ng)��(zh��ng)��(y��u)��(sh��)������������䅢��(sh��)Ҫ�ׂَ�(g��)��(sh��)����(j��)�����о��ˆT�ڻ���ģ����ʹ�ô�s1200�f(w��n)��(g��)����(sh��)��(l��i)��(sh��)�F(xi��n)64.4 mAP����������MTML-OSG��ʹ��100����(g��)����(sh��)�r(sh��)�t����62.6��ƽ��ƽ�����ȣ�mAP�����һ�N�����u(p��ng)�������͙z����ָ��(bi��o)��
�p�م���(sh��)��(sh��)�������c��(d��ng)ǰ�����������M(j��n)�Ќ�(du��)����������о��ˆT�������J(r��n)�����@һ����܉��_(d��)���@һ�I(l��ng)���(n��i)�I(y��)����피��ˮ��(zh��n)���@Ҳ���@һ�����ă�(y��u)��(sh��)֮һ���
ԭ�ģ�
https://arxiv.org/abs/1912.04423v2
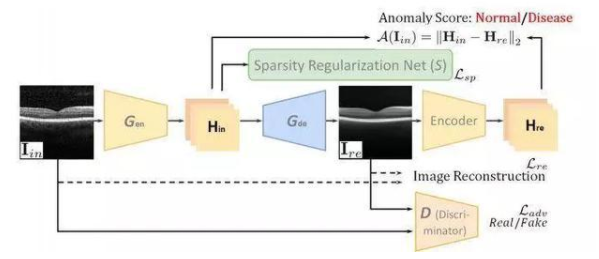
Sparse-GAN��ҕ�W(w��ng)ĤOCT�D���z�y(c��)�еđ�(y��ng)��
CNN�ȼ��g(sh��)ʹ���҂�������Ӌ(j��)��C(j��)ҕ�X(ju��)���g(sh��)����ȌW(xu��)��(x��)������(l��i)�z�y(c��)ҕ�W(w��ng)ĤOCT�D���еIJ�׃����� �����������@�ӵķ�����Ҫ�����Ĕ�(sh��)��(j��)��(l��i)�M(j��n)��Ӗ(x��n)�����������ȌW(xu��)��(x��)��(y��ng)��Ҳ������˱����������t(y��)�W(xu��)�D����������������҂�����ԭ��͕�(hu��)�l(f��)�F(xi��n)���ľ���һ�N��N�����Ĕ�(sh��)��(j��)����Ӗ(x��n)������(l��i)����ȌW(xu��)��(x��)ϵ�y(t��ng)�o(w��)���z�y(c��)������Ӗ(x��n)�����Л](m��i)�г��F(xi��n)�^(gu��)�ļ�����
���˽�Q�@һ��(w��n)�}������Image-to-Image GAN��ע��GANָ���ǡ���(du��)����(j��ng)�W(w��ng)�j(lu��)�����Ć��l(f��)�������о��ˆT�F(xi��n)�ڽ��h���@�(xi��ng)�����в���Image-to-Image GAN�M(j��n)���t(y��)�W(xu��)�D��Į����z�y(c��)��������h���ؽ��D��ӳ�䵽�������g�����������Ӿ��a���Ԝp�وD������Ӱ푡�
�c��ͬ�r(sh��)������о��ˆT��߀���hҎ(gu��)��������������ϡ���ԣ���?x��n)Hʹ������Ӗ(x��n)����(sh��)��(j��)��(l��i)�ʬF(xi��n)���^��ϡ��s�����Ɍ�(du��)���W(w��ng)�j(lu��)��Sparse-GAN��������Դ��M(j��n)�ЈD���z�y(c��)��
��OCT�����������(l��i)�Խ�����ԇ�ߵ�3D������ṩ��(sh��)�ق�(g��)��B���衱�D����o(w��)�p��������҂�����׃ҕ���(l��i)�Խ�����ԇ�ߵĮ����D�������������ʹ�Û](m��i)�в�׃��OCT ��B���衱��(l��i)Ӗ(x��n)�������z�y(c��)ϵ�y(t��ng)����
Sparse-GAN�܉��A(y��)�y(c��)���g�Н��ڵĮ�����������LjD��(j��)�e�Į�������������߀�ܵ��·f��Sparsity Regularization Net�ļs�������ڿɹ��_(k��i)�@�õĔ�(sh��)��(j��)���ό�(du��)���M(j��n)�е��u(p��ng)�����������������܃�(y��u)�ژI(y��)�����·����������
Ҳ�����f(shu��)����Sparse-GAN�����ڼ����Y�飬����Ӗ(x��n)������ֻ�н�����(sh��)��(j��)����������@�ӣ����Ԝp�p��(sh��)��(j��)�ռ���עጵ��y��������ԓ����߀�����A(y��)�y(c��)��������D����������@ʾ��׃���M(j��n)���R���\�ࡣ
ԭ�ģ�
https://arxiv.org/abs/1911.12527v2
��������Փ��
��һ��(g��)�܉�ͨ�^(gu��)��һҕ���جF(xi��n)���g3D���ֵķ�����
https://arxiv.org/abs/2001.02149v1
PaRoT��һ��(g��)����TensorFlow��ȫ��ϵ�y(t��ng)��
https://arxiv.org/abs/2001.02152v1
ȫ�µ�������F(xi��n)��(sh��)�ġ������P(gu��n)ע���R(sh��)�ı���������
https://arxiv.org/abs/1912.11238v2
��һ��(g��)�܉�����҂����õ�������ȌW(xu��)��(x��)����Փϵ�y(t��ng)��
https://arxiv.org/abs/2001.00939v2
һ�N��Ӌ(j��)��C(j��)��ȫ���I(l��ng)���б��^���u(p��ng)����ͬ��ጷ����Ę�(bi��o)��(zh��n)��
https://arxiv.org/abs/1906.02108v3
��(sh��)��(j��)��
��(sh��)��(j��)������ô��(l��i)�ģ�
https://arxiv.org/abs/1803.09010v5
ʹ��VizWiz��(sh��)��(j��)���g�[�������͞g�[һ�M���͙C(j��)���W(xu��)��(x��)��(sh��)��(j��)����
https://arxiv.org/abs/1912.09336v1
AI���¼�
AI����Ύ����҂�?c��)��Ї?gu��)��(zh��n)��ؚ���ģ�
https://time.com/5759428/ai-poverty-china/
���㷨�����ҵ�����x�
http://news.mit.edu/2019/finding-good-read-among-billions-of-choices-1220
����AI�����c���M(f��i)�ߵ�(li��n)ϵ��
https://www.forbes.com/sites/forbesagencycouncil/2020/01/08/leveraging-ai-to-enhance-connection-with-consumers-12-techniques-for-marketers/#5fbdbd70cb69
��(du��)������(gu��)��˾��(l��i)�f(shu��)��������(gu��)������(sh��)�(y��n)�ҕ�(hu��)Խ��(l��i)Խ�y��
https://www.wired.com/story/export-controls-threaten-ai-outposts-china/?utm_brand=wired&utm_social-type=earned
MIT�_(k��i)�l(f��)�����ЌW(xu��)����AI���n�������A(y��ng)I�����ͻ��A(ch��)֪�R(sh��)��
http://news.mit.edu/2019/bringing-artificial-intelligence-and-mit-middle-school-classrooms-1230