����������
ϵ��highspeedlogic
QQ ��1224848052
�ţ�HuangL1121
�]�䣺1224848052@qq.com
�Wվ��http://www.mat7lab.com/
�Wվ��http://www.hslogic.com/
�Œ�һ�ߣ�

������V
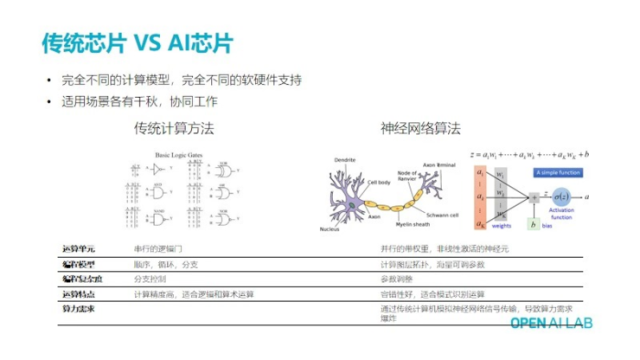
1 ���yоƬ VS AIоƬ;
2 AIоƬ��ʹ�c -- �����_ʼ��ܛ���_�l����;
3 �����_�lʹ�c -- оƬ��Ƭ��;
4.Tengine�_�ŵ�AIoTܛ���_�lƽ�_��
����open AI lab��Tengine�aƷ���B���O���\���IJ���ֱ�����팍䛣���AIͶ�а�ڲ���׃ԭ��Ļ��A�����������;����������������Ո�Pע��AIͶ�а���T���ݡ�
�gӭ��ҁ����h�W�����ҵ��v�����ұ����v�����}��AIOTоƬ�İlչڅ���c������ء����������ҽ�Bһ�µģ��ҽи��\������open AI lab��Tengine�aƷ���B���O����֮ǰ��Ƕ��ʽ��AI���g���ң�֮ǰ����arm���μ��g�Ј�������ؓ؟arm���g���ƏV��������֮ǰ�nj���оƬ�ИI�ģ����Ԍ�AIоƬ�@һ�K�˽���^�࣬Ȼ��F����Ͷ����AIܛ���đ����_�l�c��أ�����Ҳ���^�����ã�����@�νo��ҷ����@�����}��
�@�ε����}��AIOTоƬ�͑�����أ���֪����ҿ����@�����}��ô��ģ��䌍оƬ�c��������@�ǿ�ȷdz���ăɼ����飬���оƬ��̎�ڼ��g����a�I��Ϸdz����εļ��g�aƷ�����̘I������t�Ƿdz����ε�ƫ�̘I���̻���һ���¡������䌍�ɼ������ȷdz����ұM������\���o��ҽ�������ǰAIоƬ�Լ���ص�һ����r��
�����Ƚo��ҽ��һ�£�AIOT�@���~��Ԓ���ꑪԓ���Ƿdz����T��һ���~�ˣ�����AI��LOT���@ôһ�����AI���˹����ܣ�LoT�����W,��ôAi+LoT�ļ����������f�ﻥͬ�r��ÿһ�����w������һ����AI���ǻ��������܉��M��logo�Ĵ惦��������ô��AI��LoT���g�Y�������ĕr��������һ�����g�Ĵl�����������ȁ��o��ҷ���һ�t���쿴��������˼���������Ǹ炐�ȁ���Wһ����ʿ��˹�ٷ�J cook���������l��1ƪՓ�ĵؿ�������nature�ķ������棬Փ�ĵă������f�����˰���r�g���L�L����һ���F�ɵ��ĈD�V��
�䌍�@�Ƿdz������һ�����顣�����Ŀǰ�˹�����ֻ���W�j�@ôһ���ƌW���䌍�����@����ĿƌWԭ�����˂����]����������Ŀǰ���ֻ�ǏĹ��̌W�ĽǶȰl�Fͨ�^�����W���W�j��ͨ�^�@�N��ʽȥ���̣����_���dz��õ�Ч������ô����ȥʹ���ˣ������ԭ���䌍һֱ���������ô�@�ε�Ԓ���x����һ�������c���ھ����f�������w���Y���dz����Σ�����ֻ��һǧ�����������д�s1/3Ҳ��300�����X������Ҳ������Ԫ��Ȼ�����е���Ԫ�B��ֻ��7000������ô�䌍��һ�����҂����f�ѽ���һ�����^���ε��W��
ͨ�^�W�j�Y����300����Ԫ��7000���W�j�Y�����Ϳ��ƾ��x�����\���ʳ��Ȼ�������]�⣬߀����ֵ�ȵ����ԣ������������wϵ���@�װق������ơ���ô�䌍����f�҂��܉�ͨ�^�о��F�ɵ���ϵ�yϵ�y���܉�l�F�����W�j���\�еĊW�ص�Ԓ�����������W�j�ƌW�İlչ�Ƿdz������x�ġ��@��Փ�ĵ�朽Ӿ�����PPT��ų����ˣ���ҿ���ֱ����һ�£����dȤ��Ԓ�����xһ��Ӣ��ԭ�ģ����X��߀�Ƿdz������x�ġ�
�ã��҂�����һ�½�������}�����ȵ�Ԓ����o����@߅�Ⱥ��εĿ���һ�£�ʲô��AIӋ�㣿���AI�@���~��Ԓ�����ֻ��ͨ�^���ε�ý�w���������Ԓ���@���~��ԓ��һ�����^����ġ���������ҽ���������}��AIоƬ���OӋ�c��أ������@߅��С��Ҫ�����f�܉�����vһЩ���^���g������ؽӵؚ�Ė|���������Ҿ�ֻ���@߅����\���Ľo����v��Bһ��AIӋ��ԭ����
����֮ǰ���x�������f��������300������Ԫ��7000������朽ӣ�ÿһ����Ԫ��Ԓ���䌍�����ڿ���PPT�������Ͻ��L���@�ӵģ���ґ�ԓ���л�������Ҷ��W�^������һ����Ԫ���кܶ�ͻ�|Ȼ��ͻ�|���Խ��܁���������Ԫ��һ�����d�^��Ȼ�������|���d�^Ȼ���ҳ��^һ���ֵ�ĕr�����͕����d�^���f�o��һ����Ԫ����ô�@���������W�j������������һ����Ԫ��Ԫ��
�䌍�@�Ǻ�����˼��һ�����飬�����f��ͨ�^�г�ǧ���f�������σ|���@�N��Ԫ���@ôһ���B�ӣ��܉�Ϳ��������ɷdz����s�ģ�������˼�����������@�ӵĆ��}����ô�@ô���õ���Ԫ��ʽ��Ԓ����ô�҂��@һ���҂��@һ�����˹����ܵ��˳����澿�������ȥ�����͌��F���ܵĻ���ԭ����Ԓ����ҿ��Կ��ҵ�PPT�������½��@���D���½��@���D���@����ʽ���ǿ��Կ���ʲô��
�@���䌍����һ����Ԫ�Ĕ��W��ģ���䌍�Ҳ�̫���v��ʽ�����������Ŵ�������@����ʽ߀�Ƿdz��б�Ҫ�ģ��@�������������w�����v����ҿ��Կ��������f���½��@���D���棬�҂����������a1��ak�䌍�����ǁ���������Ԫ���@ôһ���d�^�Ă�����Ȼ��WE��WK�t�nj�������ÿ����Ԫ����һ���d�^��һ������ֵ����ô�����d�^�����ĕr����ԙ���ֵ��Ȼ������ۼ���������ô������Ԫ���ܵ��˿��w���d�^������Ԫ�����յ������d�^�ij��^�������Ђ��ֵ֮����ô���Լ��͕��a���d�^�����Ұ��@���d�^���f��ȥ����ô�@�ǿ��Կ����@����������߅��ݔ��Aֵ��Ҳ�����@߅����ZȻ��ͨ�^һ��Activation function�ķ�ʽ���Ǽ�����������^ij���ֵ�ĕr�����͕�ݔ��A���d�^��
�@����ͨ�^�Ԕ��W�ķ�ʽ��ģ�M��Ԫ��ô�ǷN�d�^��������ô��ʲôҪ���@����ʽ�����Ո��ҿ�һ�£������f�@߅Z��Ӌ����ͨ�^A��W1��Ȼ���ټ���A2��W2���зdz������K�����ۼӣ����dz˷��ĽY�������Ұ����ۼ���������ǂ��Y�������Ծ����fһ����Ԫ���Ͱ�����K�����ۼӲ��������ۼ��@��������һ��Ҫӛס���������Ԓ���෴�Ͷ���ᵽ�@�����
���½��@������ֻ�ǽ�����fһ����Ԫ���҄����ᵽ���f�҂����x����300������Ԫ����������B�ӵģ���ô�@���B�ӣ��Ϳ��Կ�����PPT���Ͻ��ǂ��D���@�����ϽLjD��Ԓ�ǿ��Կ������gÿһ��С�AȦ���oՓ���{ɫ���tɫ߀�ǾGɫ���䌍����һ����Ԫ���@����Ԫ�����܁���������߅��һ�ӵĸ�����Ԫ�Ĵ̼���ͬ�r�����������d�^�½o����߅����Ԫ��
���Կ������@���D�����Ԓ����һ��һ�ӣ�ÿһ���ж�����Ԫ��Ȼ��ͨ�^�@�N��ʽ�Ϳ��Ԯa��һ����Ԫ�ļ������Ӵηdz��࣬�҂���������ȣ���ô�@��������W�j��һ�������Ĕ��Wģ�͡����Կ��������fһ����Ԫ������K�����ۼӣ���ô���@ô����Ԫ���͕��зdz�����ۼӡ��������Ͻ��@���D���Ǵ�������Ԫ���e��һ�����W��ģ���ڌ��H���È������棬�҂������������@�ӵ�ģ�ͣ����ε�DNN��������W�j�����Hʹ�õ�Ԓ���҂������Ï��s��ľW�j����ô���½��@���D�䌍�Ǐķdz�����ģ������@һ���˹������d����_ɽ�����Փ�ģ�����ժ���������ľW�j�Y�����ؓ�D����ҿ��Կ��������f�@�������������˺ܶ��ӣ������аˌ������傀���e�ӣ�����ȫ���g�ӣ�Ȼ���c��֮�g������Ԫ��朽ӣ�Ȼ��ÿһ�Ӷ��Ўװق���Ԫ����ô�����W�j��������60�ף�Ҳ����60�����f�ą�����
�����M���@ôһ��ǰ��Ӌ�����720��һ���͙z������720��������Ӌ������֮����������ʲô���������R�e����һ���D���M�з���R�e���@�Dz���һ��؈���R�e�@�Dz���һ���O����һ�v����܇��һ����܇�ȵȡ������f�@�䌍����һ������������W�j������ε�һ�����������AlexNet�W�j��720�ׂ�Flops�IJ������@�Ƿdz����һ��Ӌ�㣬��ô��ʲôҪ���{�@���������������W�jӋ���Е�����ô����ۼӲ��������Ԃ��y��Ӌ��C�ΑB�ѽ����m��ȥ���@�ӵ��\���ˡ���ʲô���m���@߅�ٽo��Ҿ��f����720�ף���ô���O����һ��1G��Ɲ�ģ�Ȼ��һ�����������Ă����ۼ��\����@ôһ��cpu��Ԓ����Ҫ����ȥ�\��180���룬�����܉��M��һ��ǰ��Ӌ�㣬180�����Ԓ��������������ֻ��������һ���R�e�ٶȣ���ô�ںܶ����È����䌍�Dz��M������ġ�
�����Ž��^�@�ӽ�B��Ԓ����ґ�ԓ���W�jӋ����һ�����Ե��J�R�����ǃ��c����������ģ����Ԫ�ģ�������зdz���ij��ۼ��\�㡣�����@߅�͒���һ�������ĸ�������f���yоƬ��AIоƬ����һ����ȫ��ͬ��Ӌ��C��ģ�ķ�ʽ������������ȫ��ͬ��Ӌ�㷽ʽ��������Ҫ��ȫ��ͬ��һ�NܛӲ��ȥ֧�֡���ô�f��ȫ��ͬ���Ҳ�֪�� �������ж�����Ӌ��C�wϵ�Y�������ģ����njW�����·��߉�WӋ��C�wϵ�Y�������njWcpu�OӋ�����ģ���ô�ҏĴ�W�_ʼ�W�����c����T��ͨ�^�ǷN߉����ȥ���F���s߉��
��ô��ҿ��Կ��������f���ҵ�PPT���棬��벿�ֵ�Ԓ���ھ���һ�����y��оƬ�����������һ��Ӌ���Ԫ���Ƿ��T�c�T���T��Ȼ��ͨ�^�@�ӵ�߉��Ԫ���҂�ȥƴ�ӳ��ӷ������˷������������������Ǵ惦����Ȼ����ͨ�^�Ӝp�˳���߉��֧���D�M�г�����\�㣬Ȼ��ͨ�^��������Ŀ��ƣ�Ҳ��ͨ�^���ѭ�h��֧���������W�^C�Z��C++�@�N������ij����OӋ������������Ӌ��C�Y�������T�Z�����������Ӌ��C��Փ��Ҳ�͏�40������ǰ�𣬾���һֱ��ѭ�@����Փ��ͨ�^���ѭ�h��֧�ķ�ʽ�����ӏ��s����ɸ��N���ӏ��s���ܡ���ô�����@�N���yӋ��C��ʽ�����ă���������Ӌ�㾫�Ⱥܸߣ������������·ȥ���F�ģ�����������0����0,1����1���������m��߉�\������g�\�㡣�W�jӋ���ǰ��o��ҽ�B�^��������ȫ��һ�ײ�ͬ��Ӌ�㷽ʽ�����Ļ����\���Ԫ��һ�����еĎ����صķǾ��Լ������Ԫ��Ȼ�����ľ���ģ��Ҳ��������yӋ��Cһ�ӵ����ѭ�h��֧������һ����Ӌ��D�ӵ��ؘ�Y���OӋ���Լ����溣���Ŀ��{�ą�����߀ӛ��ӛ��ǰ��AlexNet���ٌӣ�����60�ׂ����������档
��������������ȥ�{�������OӋ���N��Ԫ�M�й�������ô�������̏��s��Ҳ���w�F���{�����棬�䌍��һ�����^��Ц�ģ������f�F�����㷨���ˣ����������ԷQ�Լ��Ǿ���ʽ��Ӗģʽ�������ڲ�ͣ���{�������{�����@����������һ�����^���W�ģ���Փ���A���Ƿdz����ģ��������c���\�����c��һ�ӡ�Ȼ���W�j�㷨�ă��c�����e�Ժܺã���ij����Ӌ�T�����������ˣ�������������һ�����^�õ�׃�ΙC�ƣ��@�ӵ�Ԓ������ʹһ����ij����Ԫ����������������Ȼ�܉�ܺõ�work�����ұ��^�m��ģʽ�R�e��
����һ�����c���f�������䌍����������r���f��Ԓ���W�j��ԓ��һ�N�dz���ЧӋ��ģʽ������ҿ��������҂����X�䌍Ҳ�Ϳ���������������W��Ҳ�Ń��ߵĹ��ʣ����ǿ����M�зdz�Ӌ����s��������оƬ����ȥ��AIӋ�㣬��ȫ���Dz��������@��ģʽ�����Dz��Â��yӋ��C߀�����c����T߉������ij˷������˼�������ģ�M�W�j��̖��ݔ���@���������������ı�ը�����һ����Ԫ�҂����ܾ�Ҫ��N���˷��˼Ӳ�����
������@�ӵ�������ը�����Ծ������_�l���T��AIоƬ�����@߅��Ԓ�ҽo��ҷ������D���քe��CPU�� DSP ��GPU��߀�ЬF�����W�j̎��������dz���Ҋ����С��@���N�քe�����ˬF��ȥ���W�jӋ���@ôһ�����F���ܡ�
�����Ȼش�һ�����}���䌍�F�ڴ���Ђ����R�������f���ycpu�Dz���ô���m�Á���AIӋ��ģ��@�Ǟ�ʲô���䌍��ԭ���ρ��f��Ԓ���ĈD����ͺ������܉���ǰ�����ᵽ�����f�W�jӋ����������д����ij˼Ӳ������˼Ӳ�����cpu�����Ԓ�������g�@��Ԫȥ�M���\��ģ������½ǿ��������Ͻǣ��ɾGɫ����AIUȥ�M�г˼Ӳ����ģ���ôһ��cpu����˼ӵĆ�Ԫ����������ͨARM cpu��������fcos A72���������Ԓ�����ɽ���Ԫһ������ֻ�����Ă����c�ӣ���������f�������ε�Ԓ���ܕ���һЩ�����а�λ���ε�Ԓ�����˂���
���CPU����ҪĿ������ͨ�ÿ��ƣ������㿴�����ܶ��Ӳ��߉�ڿ������棬���ԾͿ���оƬ����߅���{ɫ���@���������ܴ�һ���ֵĿ��Ɔ�Ԫ�����档�䌍�����f��CPU�������������д�����߉���M���������\�㣬���������˼��\���߉���ֵľGɫ���־ͺ��٣�������CPUȥ���˼��\��Ч�ʲ��ߡ����Դ�Ҷ��f����CPUȥ��AIӋ�㲻���m���䌍�����ķ�����PC��������GPU��AIӋ��ģ���ô���������g�@���D����
GPU���OӋ���c���д�����С�Ć�Ԫ�����ε�ALU���ǾGɫ���֣��д�����С�Ć�Ԫȥ��Ӌ�㡣��ͬ�r���Ŀ���߉���dz�С�����Կ�������{ɫ���Sɫ���֣�������GPU��AIӋ���CPU�ߺܶ࣬���^����J��GPU�����ܸߣ��䌍��ֻ�������漉��NV��GPU���������ʕ��dz��ߡ�
�������ʸ������NV��gpu��������ͨ���OӋ���M�Ѓ������������ǿ�����ͨ��Ӌ��ġ���ô�������Ƕ��ʽ�ȵ�arm��gpu���棬��������һ�����Դ�dz��o��һ���h�����棬����֙C������늳صģ�����������Ҫ����߀�����D����Ⱦ���Α��õģ������д���߉�����D�εģ�������������ͨ��Ӌ��IJ��ֵĆ�Ԫ�䌍Ҳ�]�зdz��ࡣ
Ȼ��ͬ�r�������w�Ĺ������ƣ���armоƬ�����arm��gpu��ͬ����ͬһ�KоƬ������һ��CPU�����������䌍�Dz����һ��level�ģ�����һ������߀��һ�����������@ôһ�������ô�䌍�@߅Ҳ�������ᵽ�fgpu�����Ԓ���䌍�Ѓɂ����ܣ�һ���ֹ��ܿ�����ͨӋ�㣬һ���������D��̎������ô����҂���GPU��ͨ��Ӌ���Ԓ���D��̎���@���ֵ�߉�䌍�������M�ˣ�����gpu��Ч���䌍Ҳ������ߵġ�
��ô�䌍�F����һЩNPU���OӋ�����T���Wվȥ�OӋ��Ԓ������һ���ܺ��γ��l�c߉�����ǰ�gpu�����c�D�����P�IJ���ȥ������ôͨ�^�@�N��ʽֱ�Ӱ�һ��GPU�����һ����AIӋ���NPU����GPUȥ��AIӋ�㣬�䌍��ȻЧ�ʲ�����ߵģ�������gpu��һ����Ҏģ�ɾ��̵�һ��ͨ��Ӌ��Ć�Ԫ�����]��ᘌ�AI���@�N��Ҏģ�˼��\����ȥ���Mһ��������
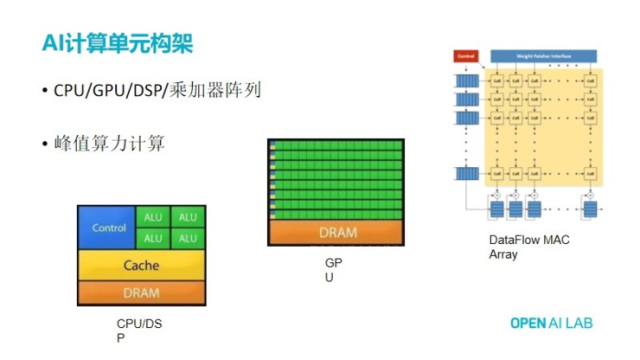 �@߅��Ԓ�͵�Ҫ��ʾ�f�����ᘌ�AI�@�NӋ����ᵽ��Ҏģ�ij˼��\�㣬�䌍��������D������S�����ˡ������˵�Ԓ��Ӌ�㷽ʽ�Dz����}����У���dataflow�������@�N��ʽ��ͨ�^�OӋһ�ѳ˼������M��Ӌ�㡣��̎�����ѿ���߉����������ͣ���������˾����˵�ÿ��ȥ�˼��@ôһ�����ԣ���ô����Ⱥ��������Ŀ���߉���@�ӿ��Ԍ��������˼�����Ч�ʷdz��ߣ�����Կ�������оƬ�����ȫ���dz˼���������߉�ͺ��١�
��߅�}����У����Oÿһ��С������������һ���˼��������O��һ��100��100��size��Ԓ��������1�f���˼����ˡ��҂��ٻ���һ�£������҂��Ͱ˂��˼���.�˺�һ�f���ǺÎׂ��������IJ�ࡣ����ֻ�Ǐ���Փ�Ͻ�ጣ��F���fһ���H�a�I���棬AI������оƬ��Ԓ�����Dz����ķN������?����AI��������Щ�Dz��Ì����·�OӋ�ģ����Կ��������ϽǵĔ����}����У���ȸ��GPUһ���Dz����@�N���ܵġ�
�@߅��Ԓ�͵�Ҫ��ʾ�f�����ᘌ�AI�@�NӋ����ᵽ��Ҏģ�ij˼��\�㣬�䌍��������D������S�����ˡ������˵�Ԓ��Ӌ�㷽ʽ�Dz����}����У���dataflow�������@�N��ʽ��ͨ�^�OӋһ�ѳ˼������M��Ӌ�㡣��̎�����ѿ���߉����������ͣ���������˾����˵�ÿ��ȥ�˼��@ôһ�����ԣ���ô����Ⱥ��������Ŀ���߉���@�ӿ��Ԍ��������˼�����Ч�ʷdz��ߣ�����Կ�������оƬ�����ȫ���dz˼���������߉�ͺ��١�
��߅�}����У����Oÿһ��С������������һ���˼��������O��һ��100��100��size��Ԓ��������1�f���˼����ˡ��҂��ٻ���һ�£������҂��Ͱ˂��˼���.�˺�һ�f���ǺÎׂ��������IJ�ࡣ����ֻ�Ǐ���Փ�Ͻ�ጣ��F���fһ���H�a�I���棬AI������оƬ��Ԓ�����Dz����ķN������?����AI��������Щ�Dz��Ì����·�OӋ�ģ����Կ��������ϽǵĔ����}����У���ȸ��GPUһ���Dz����@�N���ܵġ�



����AI�a�Iһֱ��׃�������У�����ֻ��Q�˾��e�������H�����ИI�����������и��N���ӵ��������ӣ����������֕������и��³��������Ҫ��Ӳ��һ����һ���ɾ��̵ġ����ԽY�����}����������e�@�N��Ч�Ϳɾ��̵�������ôĿǰ���������е�AI���������OӋ�ѽ���������;ͬ�w�ˣ����Ã��߽Y��,һ�KоƬ����ļ��пɾ��̲��֣�������һ��ǰ���ᵽ�˰�GPU�шD�β��ֲü���팍�F��Ҳ����ͨ�^����һ�N����ͨ�^DSP�ķ�ʽ�팍�F��
|