功能描述:
二:viterbi譯碼器
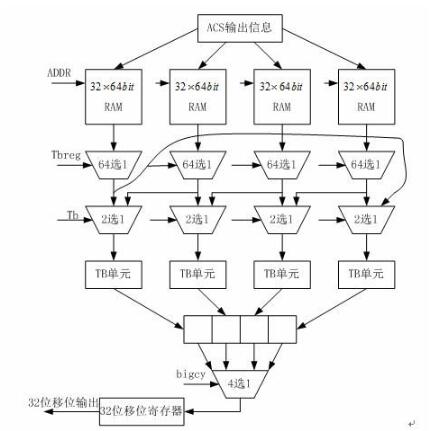
(2,1,7)卷積碼譯碼過程的總體結構可分為4個子模塊,分別是分支度量模塊,加比選蝶形運算單元,幸存路徑存儲單元和回溯譯碼單元。
譯碼器的結構框圖如圖3所示。

·分支度量計算單元
分支度量計算單元是用來計算輸入信號序列與卷積碼各個可能輸出信號序列的似然度量,維特比的似然準則就是在尋找具有最小距離的路徑。若譯碼器采用硬判決譯碼時,分支度量計算采用漢明距離,而采用軟判決譯碼時,則是采用歐氏距離,即計算

采用這種方法,與采用歐氏距離相比,對譯碼器的性能影響不大,該譯碼器的性能與采用歐氏距離的譯碼器性能差僅有0.1~0.2dB。
由上式可以看出,如果采用8電平量化軟判決方式,則此時路徑度量值擴展為0到14,所以分支度量單元的輸入是3比特數據,而輸出則是4比特數據,這樣硬件實現比較簡單,可以減少硬件開銷。
其硬件實現電路結構如圖4所示。由于本設計中采用的是(2,1,7)卷積碼,所以一級中共有64個結點,需要64個分支度量計算單元,在實現中,采用了全并行的結構,這樣在一個時鐘周期內,可以更新所有64個結點的分支度量值。

圖4 分支度量計算單元的硬件電路結構
其代碼如下所示:

assign I = (en) ? Iin : 0; //軟判決輸出模塊
assign Q = (en) ? Qin : 7; //軟判決輸出模塊
assign recom = reset &en | start;
wire [3:0] bm0,bm1,bm2,bm3;
assign bm0=bm00(I,Q);//BM模塊的輸出
assign bm1=bm01(I,Q);//BM模塊的輸出
assign bm2=bm10(I,Q);//BM模塊的輸出
assign bm3=bm11(I,Q);//BM模塊的輸出
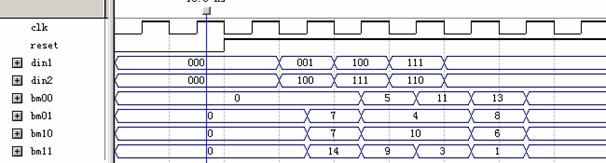
其仿真結果如下所示:
·加比選模塊
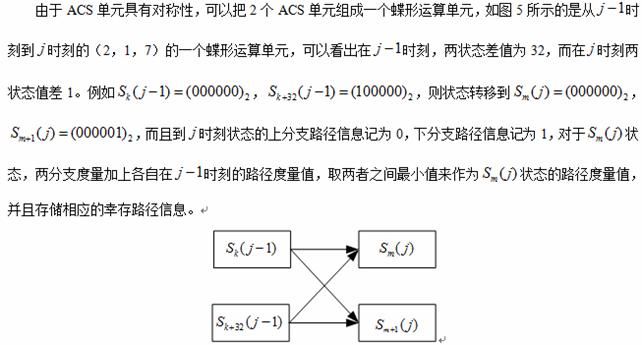
圖5 ACS蝶形運算單元框圖
通過對加比選過程的分析,可以發現每次分支度量值都是非負的,因此分支累計度量值是不斷增加的,由于在硬件實現中不能不考慮分支累計度量值的位寬,因為在硬件實現時該值需要存儲在有限位寬的寄存器,所以需要對累計度量值進行歸一化運算,以防止在累加過程中發生數據溢出,常用的控制方法是在每一步運算后首先找出所有狀態節點的累計度量值中最小的一個,最后要減去該最小值,這種方法的主要缺點是每次加比選運算后都要對更新后的累加結果進行大量的比較操作,以找出最小累計度量值并將其置0,其余累計度量值與該最小值相減后得到的結果存儲下來,以供下一次加比選操作使用。維特比譯碼器的譯碼輸出只與度量值的相對值有關,每一步的路徑度量值的最大值與最小值滿足下面的關系:

在本設計中采用補碼加法運算方法可以自動完成歸一化中的求模運算,其電路結構如圖6所示,其中比較器電路結構如圖7所示。

ACS模塊的代碼如下所示:
module ACS(
din_a, //BM模塊
gama_a, //前一時刻64個狀態的路徑量度
din_b, //BM模塊
gama_b, //前一時刻64個狀態的路徑量度
gama_out,//路徑量度輸出
sel //幸存選擇
);
input [3:0] din_a;
input [3:0] din_b;
input [7:0] gama_a;
input [7:0] gama_b;
output [7:0] gama_out;
output sel;
wire [7:0] m1,m2;
wire cmp;
wire flag;
assign m1=gama_a+{4'b0,din_a};
assign m2=gama_b+{4'b0,din_b};
assign cmp=(m1[6:0]>m2[6:0])?1:0;//比較選擇
assign flag=m1[7]^m2[7];
assign sel=flag^cmp;
assign gama_out=(sel)?m2:m1;
endmodule
其中我們需要調用ACS模塊64次。
ACS ACS_u1(
.din_a(bm1),
.gama_a(PM1),
.din_b(bm2),
.gama_b(PM33),
.gama_out(pp1),
.sel(sel1)
);
…………………………………..
ACS ACS_u64(
.din_a(bm1),
.gama_a(PM32),
.din_b(bm2),
.gama_b(PM64),
.gama_out(pp64),
.sel(sel64)
);
·幸存路徑存儲單元
(2,1,7)卷積碼每向前譯碼一位要產生64位的幸存路徑,所以我們用一個64位寬的RAM來存儲ACS產生的幸存路徑信息。在回溯的過程中,也就是從RAM中讀出幸存路徑值來決定回溯的路徑。
//最小路徑量度狀態選擇
assign survival={
sel1 ,sel2 ,sel3 ,sel4 ,sel5 ,sel6 ,sel7 ,sel8 ,sel9 ,sel10,sel11,sel12,sel13,sel14,sel15,
sel16,sel17,sel18,sel19,sel20,sel21,sel22,sel23,sel24,sel25,sel26,sel27,sel28,sel29,sel30,
sel31,sel32,sel33,sel34,sel35,sel36,sel37,sel38,sel39,sel40,sel41,sel42,sel43,sel44,sel45,
sel46,sel47,sel48,sel49,sel50,sel51,sel52,sel53,sel54,sel55,sel56,sel57,sel58,sel59,sel60,
sel61,sel62,sel63,sel64
};
·回溯譯碼單元
回溯譯碼單元是本設計的重點,其回溯單元框圖如圖8所示:
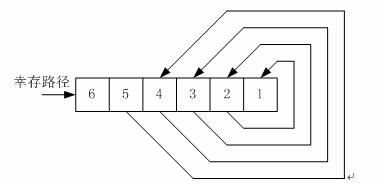
圖8 回溯單元結構圖
在本設計中回溯譯碼單元如圖9,回溯譯碼共用4塊32*64bit的RAM,在回溯譯碼單元有兩個計數器,其中模32加法計數器產生RAM的寫地址add32,模32減法計數器產生回溯過程中RAM的讀地址sub32。
另外還有一個模4的計數器產生四塊RAM的讀寫控制信號,當譯碼開始后,幸存路徑首先存儲在第一塊RAM中,然后存儲第二塊RAM,當進行到第64個時鐘周期時,第二塊RAM存儲完畢,然后開始存儲第三塊RAM,同時從第二塊RAM中開始回溯,當運行到96個時鐘周期時,第三塊RAM存儲完畢,第二塊RAM也回溯完畢,然后開始存儲第四塊RAM,同時第一塊RAM 開始回溯,這時回溯出的信息就是正確的信息,這樣循環執行,可以保證四塊RAM中有兩塊RAM在回溯過程中。

一塊RAM在存儲幸存路徑。其中四塊RAM的輸出對應一個64選1的MUX,并且它的輸出還要經過一個2選1的MUX選擇輸出,然后再輸入到回溯單元,回溯單元通過一個簡單的移位操作,回溯到前一個狀態,回溯輸出通過一個4選1的MUX選擇輸出的就是譯碼輸出,并寫入到32bit的寄存器中,每32時鐘周期一次輸出32bit的回溯信息結果,我們這里存儲下32bit的回溯信息后,然后每個時鐘周期輸出一個比特的譯碼信息。在設計中卷積碼的譯碼回溯深度最小為32,最大為64。
//幸存信息管理
sram sram_u1(
.address (add1),
.clock (clk),
.data (survival),
.wren (wen[0]),
.q (dout1)
);
sram sram_u2(
.address (add2),
.clock (clk),
.data (survival),
.wren (wen[1]),
.q (dout2)
);
sram sram_u3(
.address (add3),
.clock (clk),
.data (survival),
.wren (wen[2]),
.q (dout3)
);
sram sram_u4(
.address (add4),
.clock (clk),
.data (survival),
.wren (wen[3]),
.q (dout4)
);
reg val_out;
reg valid;
always @(posedge clk or negedge reset)
begin
if(!reset)
begin
val_out <= 0;
valid <= 0;
end
else
begin
val_out <= val;
valid <= val_out;
end
end
reg [2:0] count1;
always @(posedge clk or negedge reset)
begin
if(!reset)
count1 <= 0;
else if(val_out)
count1 <= count1 + 1;
else
count1 <= count1;
end
reg [2:0] count;
always @(posedge clk or negedge reset)
begin
if(!reset)
count <= 0;
else if(val_out)
begin
if((count<=3)&(count1==0))
count <= count + 1;
else if((count==4)&(count1==0))
count <= 1;
end
else
count <= count;
end
reg [31:0] decoke_out;
always @(posedge clk or negedge reset)
begin
if(!reset)
decoke_out <= 0;
else if((val_out)&(count==0)&(count1==0))
decoke_out <= decoke;
else if((val_out)&(count==4)&(count1==0))
decoke_out <= decoke;
else
decoke_out <= decoke_out;
end
function [7:0] dout;
input [31:0] dec;
input [2:0] sel;
begin
case(sel)
3'b001:dout=dec[31:24];
3'b010:dout=dec[23:16];
3'b011:dout=dec[15:8];
3'b100:dout=dec[7:0];
default:dout=0;
endcase
end
endfunction
assign dataout=val_out?dout(decoke_out,count):0;
聯系:highspeedlogic
QQ :1224848052
微信:HuangL1121
郵箱:1224848052@qq.com
網站:http://www.mat7lab.com/
網站:http://www.hslogic.com/
微信掃一掃:

--------------------------------------------------------------------------------------
人工智能代做,深度學習代做,深度強化學習代做,zynq智能系統FPGA開發,
AI代做,卷積神經網絡,Alexnet,GoogleNet,CNN,TensorFlow,
caffe,pointnet,PPO,Qlearning,FasterRCNN,MTCNN,
SPPNet,word2vec,SARASA算法,梯度策略等等