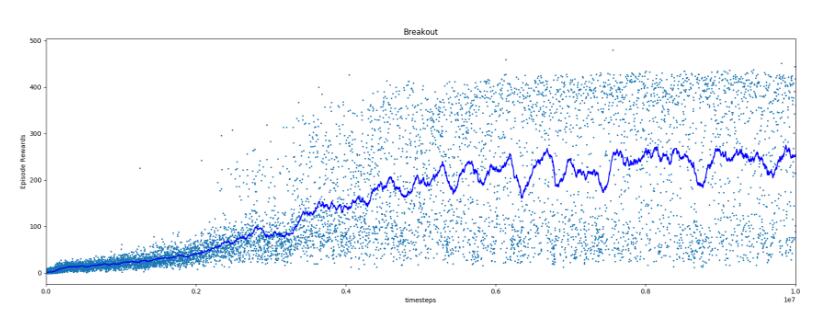
����������
OpenAI��Ʒ��baselines�Ŀ�ṩ��һϵ��deep reinforcement learning��DRL����ȏ����W(xu��)��(x��)����������W(xu��)��(x��)���㷨�Č��F(xi��n)���F(xi��n)���ѽ�(j��ng)�а���DQN,DDPG,TRPO,A2C,ACER,PPO�ڃ�(n��i)�Ľ�ʮ�N��(j��ng)���㷨���F(xi��n)��ͬ�r��Ҳ�ڲ����U���С����錦DRL�㷨�ď�(f��)�F(xi��n)��C���Č���ṩ�˺ܴ�ı�����������Ҫ���x���е�PPO��Proximal Policy Optimization���㷨��Դ�a���F(xi��n)��PPO��2017����OpenAI�����һ�NDRL�㷨�������H�кܺõ�performance�������nj����B�m(x��)���Ɔ��}����ͬ�r���^��֮ǰ��TRPO�����������ڌ��F(xi��n)��֮ǰ���^һƪ�s�ġ���������W(xu��)��(x��)��DRL����Մ - ��ه��Trust Region��ϵ����������vʷ��ԭ�������P(gu��n)�������˺��ν�B����˱�����Ҫfocus�ڴ��a���F(xi��n)�ČW(xu��)��(x��)�˽��ϡ�
OpenAI baselines�Ŀ�Ќ���PPO�㷨�Ѓɂ����F(xi��n)���քeλ��ppo1��ppo2Ŀ��¡�����ppo2������GPU���ٵģ��ٷ�̖�Q�����������ң�����������Ҫ�ǿ�ppo2������(y��ng)Փ�Ğ顶Proximal Policy Optimization Algorithms�������º��QPPOՓ�ġ������҂�����atari�@����(j��ng)���DRL������������һ�´��w���̡�����Ӗ(x��n)����������readme���У�
def main():
# ���F(xi��n)λ��common/cmd_util.py������Ҫ��parser���ӎׂ�����(sh��)��
# 1) env:����Ҫ��(zh��)��atari�е��Ă��Α�h(hu��n)����Ĭ�J(r��n)��BreakoutNoFrameskip-v4��������u�K����
# 2) seed���S�C�N�ӡ�Ĭ�J(r��n)�飰��
# 3) num-timesteps��Ӗ(x��n)�����l��(sh��)��Ĭ�J(r��n)��10M�Ρ�
parser = atari_arg_parser()
# ͨ�^����(sh��)�x��policy network����ʽ�����F(xi��n)��policies.py��Ĭ�J(r��n)��CNN���@�������N�x��
# 1) CNN������(y��ng)����(sh��)��CnnPolicy()���l(f��)���ڡ�Nature���ϵĽ�(j��ng)��DRL���Փ�ġ�Human-level control through
# deep reinforcement learning����ʹ�õ���(j��ng)�W(w��ng)�j(lu��)�Y(ji��)��(g��u)��conv->relu->conv->relu->conv->relu->
# fc->relu��ע�������p�^�W(w��ng)�j(lu��)��һ�^ݔ��policy��һ�^ݔ��value��
# 2) LSTM������(y��ng)����(sh��)��LstmPolicy()������CNN��ݔ��֮���ټ���LSTM�ӣ��@�ӾͽY(ji��)���˕r�g�����Ϣ��
# 3) LnLSTM������(y��ng)����(sh��)��LnLstmPolicy()�������ĺ�����һ�ӣ�ֻ���ژ�(g��u)��LSTM�ӕr������Layer normalization
# ��ԔҊՓ�ġ�Layer Normalization����
parser.add_argument('--policy', help='Policy architecture', choices=['cnn', 'lstm', 'lnlstm'], default='cnn')
# �Ä��ŵĘ�(g��u)����parser���������Ђ���ą���(sh��)��
args = parser.parse_args()
# �@���Ŀ�Ќ��F(xi��n)�˺��ε���־ϵ�y(t��ng)��������־����Ŀ䛺�ʽ�������^OPENAI_LOGDIR��OPENAI_LOG_FORMAT�ɂ��h(hu��n)��
# ׃�����ơ����F(xi��n)�Logger����Ҫ�Ѓɂ��ֵ䣺name2val��name2cnt�������քe�����Q��ֵ��Ӌ��(sh��)��ӳ�䡣
logger.configure()
# �@�����_ʼ��ʽӖ(x��n)���ˡ�
train(args.env, num_timesteps=args.num_timesteps, seed=args.seed,
policy=args.policy)
---------------------
def train(env_id, num_timesteps, seed, policy):
# ������һ���TensorFlow���P(gu��n)�ĭh(hu��n)���O(sh��)�ã��������(j��)cpu�˔�(sh��)�O(sh��)�����о��̔�(sh��)�ȡ�
...
# ��(g��u)���\�Эh(hu��n)��������߀���^�L���������Ԕ��(x��)�����¡�
env = VecFrameStack(make_atari_env(env_id, 8, seed), 4)
# ����(y��ng)ǰ���f�����N���ԾW(w��ng)�j(lu��)�����ڸ���(j��)����(sh��)�xȡ����(y��ng)�Č��F(xi��n)����(sh��)��
policy = {'cnn' : CnnPolicy, 'lstm' : LstmPolicy, 'lnlstm' : LnLstmPolicy}[policy]
# ʹ��PPO�㷨�M�ЌW(xu��)��(x��)�����Ђ���ą���(sh��)������ģ�͵ij�����(sh��)��Ԕ��(x��)�Ʌ�ҊPPOՓ���е�Table 5��
ppo2.learn(policy=policy, env=env, nsteps=128, nminibatches=4,
lam=0.95, gamma=0.99, noptepochs=4, log_interval=1,
ent_coef=.01,
lr=lambda f : f * 2.5e-4,
cliprange=lambda f : f * 0.1,
total_timesteps=int(num_timesteps * 1.1))
---------------------
# make_atari_env()����(sh��)���F(xi��n)λ��common/cmd_util.py��������(sh��)����֪����Ҫ���DŽ�(chu��ng)��atari�h(hu��n)����ͨ�^OpenAI gym
# ��(chu��ng)��������atari�h(hu��n)����߀��Ҫ�ӌӷ��b��gym���ṩ��Wrapper�ӿڣ��_�l(f��)��ͨ�^decorator�O(sh��)Ӌģʽ����׃�h(hu��n)���е��O(sh��)# ����
def make_atari_env(env_id, num_env, ...): # �@���num_env��8����ζ������(chu��ng)��8�������IJ����\�Эh(hu��n)����
def make_env(rank):
def _thunk():
# ��(chu��ng)����gym��(g��u)����atari�h(hu��n)���ķ��b�
env = make_atari(env_id):
# ͨ�^OpenAI��gym�ӿڄ�(chu��ng)��gym�h(hu��n)����
env = gym.make(env_id)
# NoopResetEnv��gym.Wrapper���^���ÿ�έh(hu��n)�����ã��{(di��o)��reset()���r��(zh��)��ָ�����S�C������
env = NoopResetEnv(env)
# MaxAndSkipEndҲ��gym.Wrapper���^���ÿ��4������һ�Ρ������е�reward���@����reward
# ֮�ͣ�observation������Ɏ������ֵ��
env = MaxAndSkipEnd(env)
return env
# ÿ���h(hu��n)���xȡ��ͬ���S�C�N�ӣ����ⲻͬ�h(hu��n)���ܵö�һ�ӡ�
env.seed(seed + rank)
# ���F(xi��n)��monitor.py�С�Monitor��gym��Wrapper���^������h(hu��n)��Env�M�з��b����Ҫ�����ˌ�
# episode�Y(ji��)���r��Ϣ��ӛ䛡�
env = Monitor(env, ...)
return wrap_deepmind(env, ...):
# ��(bi��o)��(zh��n)��r�£�����atari�еĺܶ��Α����@���Ĵ�u�K�����������ˣ���ԓ�Α���5�l������episode
# �Y(ji��)�����h(hu��n)�����á��@��Wrapper��������ֻҪ������step()����done�������֭h(hu��n)�����õĕr�C��׃
#����Ȼ��������r����ԭע����f�@��trick��DeepMind��DQN���Á����value�Ĺ�Ӌ��
env = EpisodeicLifeEnv(env)
# ͨ�^OpenCV��ԭʼݔ���D(zhu��n)�ɻҶȈD�����D(zhu��n)��84 x 84�ķֱ��ʡ�
env = WarpFrame(env)
# ��reward����ؓ(f��)ֵ�D(zhu��n)��+1, -1��0��
env = ClipRewardEnv(env)
...
return env
return _thunk
...
# ����SubprocVecEnv����
return SubprocVecEnv([make_env(i + start_index) for i in range(num_env)])
---------------------
��(chu��ng)��num_env��Ԫ�أ��@��飸���Ĕ�(sh��)�M��ÿһ��Ԫ�؞�һ������(sh��)�]��_thunk()��VecEnv���F(xi��n)��baselines/common/vec_env/__init__.py������һ����������������������h(hu��n)�������а����ׂ���Ҫ�ij���(sh��)��
reset()�����������Эh(hu��n)����step_async()����֪ͨ���Эh(hu��n)���_ʼ����(j��)�o��������(zh��)��һ����step_wait()�õ���(zh��)����ĽY(ji��)����step_wait()�ȴ�step_async()�ĽY(ji��)����step()����step_async() ����step_wait()����VecEnvWrapperҲ��VecEnv���^�����gym���ṩ��Wrapper������ƣ����Ҫ��VecEnv���F(xi��n)��Ĭ�J(r��n)�О����ĵ�Ԓ�Ϳ�����������
���溯��(sh��)��ص�SubprocVecEnv�VecEnv���^�������Ҫ�����愓(chu��ng)���õĺ���(sh��)�ŵ��������M����ȥ��(zh��)�С���SubprocVecEnv���F(xi��n)��У���(g��u)��r���������M���Ј�(zh��)�еĺ���(sh��)��ͨ�^Process��(chu��ng)�����M�̣���ͨ�^Pipe�M���M���gͨ�š�make_atari_env()�Є�(chu��ng)��SubprocVecEnv�������R��VecFrameStack���b��һ�ѡ�VecFrameStack��VecEnvWrapper�Č��F(xi��n)����F(xi��n)��vec_frame_stack.py����VecFrameStack�Ę�(g��u)�캯��(sh��)�У�wos��gym�h(hu��n)���е�ԭʼ��B(t��i)���g���S�Ȟ�[84,84,1]��low��high�քe���@Щ�S�ȵ���ͺ����ֵ��stackedobs���ǰюׂ��h(hu��n)���Ġ�B(t��i)���g�B�����������S��׃?y��u)?8, 84, 84, 4)��8��h(hu��n)������(sh��)��(84,84)��Ύ���B(t��i)�S�ȣ�Ҳ�����Α����Ļݔ����4�������4�������������4�Ď����Α��������W(w��ng)�j(lu��)ģ�͵�ݔ�룩��
���Կ��������������ķ��b�⣬߀��Ҫ��һЩ���^tricky�����^����(j��ng)��̎������Փ���҂�ϣ���@����Խ��Խ�ã����Խ���㷨��Խͨ�á�Ȼ���F(xi��n)�����@һ�Ktuning���Y(ji��)���ĺÉĿ��ܮa(ch��n)�����^���Ӱ푡�����
���ˣ�����ȥ�Ϳ��Կ���PPO�㷨���w�ˡ���ڞ�ppo2.py��learn()����(sh��)��
---------------------
class Model(object):
def __init__(self, *, policy, ob_space, ac_space, nbatch_act, nbatch_train,
nsteps, ent_coef, vf_coef, max_grad_norm):
# ��ǰ��ָ���ľW(w��ng)�j(lu��)��͘�(g��u)��ɂ����ԾW(w��ng)�j(lu��)��act_model���ڈ�(zh��)�в��ԾW(w��ng)�j(lu��)����(j��)��(d��ng)ǰobservation����
# action��value�ȣ���ֻ��inference��train_model���˼�x��Ҫ���څ���(sh��)�ĸ��£�ģ�͵ČW(xu��)��(x��)����
# ע���@�ɂ��W(w��ng)�j(lu��)�ą���(sh��)�ǹ����ģ����train_model���µą���(sh��)�����w�F(xi��n)��act_model�ϡ����O(sh��)ʹ��Ĭ
# �J(r��n)��CnnPolicy�����е�step()����(sh��)Ӌ��action, value function��action�ṩ����Ϣ����
# value()����(sh��)Ӌ��value��
# nbatch_act = 8���͵��ڭh(hu��n)������(sh��)nenvs�����ÿһ�ζ��քe�������h(hu��n)����(zh��)�У��õ�ÿ���h(hu��n)����actor�Ą�����
# 1��nsteps���䌍��CNN�Л]ɶ�ã���LSTM�ŕ��õ������LSTM�����]ǰnsteps������ݔ�룩��
act_model = policy(sess, ob_space, ac_space, nbatch_act, 1, reuse=False)
h = nature_cnn(X) # ��ǰ�����f����Nature���ϵľW(w��ng)�j(lu��)�Y(ji��)��(g��u)��ס�Ȼ��ݔ��policy��value��
pi = fc(h, 'pi', ...) # for policy
vf = fc(h, 'v') # for value function
# ����(j��)action space��(chu��ng)������(y��ng)�ą���(sh��)���ֲ������@��action space��Discrete(4)���Ƿֲ�
# ����CategoricalPdType()��Ȼ�����(j��)ԓ�ֲ���ͣ��Y(ji��)�ϾW(w��ng)�j(lu��)ݔ����pi�����õ��������ʷ�
# ��CategoricalPd�������ԓ�ֲ��ϲɘӣ��õ�����a0��neglogp0����ԓ����������Ϣ����
pdtype = make_pdtype()
pd = self.pdtype.pdfromflat(pi)
a0 = self.pd.sample()
neglogp0 = self.pd.neglogp(a0)
# �͘�(g��u)��action model��ƣ���(g��u)������Ӗ(x��n)���ľW(w��ng)�j(lu��)train_model��nbatch_train��256�����������ģ�͵ČW(xu��)��(x��),
# ��˺�act_model��ͬ���@���W(w��ng)�j(lu��)ݔ���batch size��256��
train_model = policy(sess, ob_space, ac_space, nbatch_train, nsteps, reuse=True)
# ��(chu��ng)��һ��placeholder���@Щ�Ǻ���Ҫ����ġ�
A = train_model.pdtype.sample_placeholder([None]) # action
ADV = tf.placeholder(tf.float32, [None]) # advantage
R = tf.placeholder(tf.float32, [None]) # return
OLDNEGLOGPAC = tf.placeholder(tf.float32, [None]) # old -log(action)
OLDVPRED = tf.placeholder(tf.float32, [None]) # old value prediction
LR = tf.placeholder(tf.float32, []) # learning rate
CLIPRANGE = tf.placeholder(tf.float32, []) # clip range������Փ���е�epsilon��
neglogpac = train_model.pd.neglogp(A) # -log(action)
entropy = tf.reduce_mean(train_model.pd.entropy())
# Ӗ(x��n)��ģ���ṩ��value�A(y��)�y��
vpred = train_model.vf
# ��vpred��ƣ�ֻ���c�ϴε�vpred���׃�ӱ�clip����CLIPRANGEָ���ą^(q��)�g�С�
vpredclipped = OLDVPRED + tf.clip_by_value(train_model.vf - OLDVPRED, - CLIPRANGE, CLIPRANGE)
vf_losses1 = tf.square(vpred - R)
vf_losses2 = tf.square(vpredclipped - R)
# V loss��ɲ���ȡ��ֵ����һ�����ǾW(w��ng)�j(lu��)�A(y��)�yvalueֵ��R�IJ�ƽ�����ڶ������DZ�clip�^���A(y��)�yvalueֵ
# ��return�IJ�ƽ�����@���ֺ�Փ�����ƺ���̫һ�ӡ���ҪĿ�đ�(y��ng)ԓ�Ǒ��Pvalueֵ���^����¡�
vf_loss = .5 * tf.reduce_mean(tf.maximum(vf_losses1, vf_losses2))
# Փ���е�probability ratio�����@���exp��logչ�_����Փ���е���ʽ��
ratio = tf.exp(OLDNEGLOGPAC - neglogpac)
pg_losses = -ADV * ratio
pg_losses2 = -ADV * tf.clip_by_value(ratio, 1.0 - CLIPRANGE, 1.0 + CLIPRANGE)
# Փ�Ĺ�ʽ(7)������ǰ�涼��ؓ(f��)̖���@����ȡmaximum.
pg_loss = tf.reduce_mean(tf.maximum(pg_losses, pg_losses2))
approxkl = .5 * tf.reduce_mean(tf.square(neglogpac - OLDNEGLOGPAC))
clipfrac = tf.reduce_mean(tf.to_float(tf.greater(tf.abs(ratio - 1.0), CLIPRANGE)))
# Փ�Ĺ�ʽ(9)��ent_coef, vf_coef�քe��PPOՓ���е�c1, c2���@��քe�O(sh��)��0.01��0.5��entropy�����е�S��pg_loss�����е�L^{CLIP}
loss = pg_loss - entropy * ent_coef + vf_loss * vf_coef
# ��(g��u)��trainer�����څ���(sh��)��(y��u)����
grads = tf.gradients(loss, params)
trainer = tf.train.AdamOptimizer(learning_rate=LR, max_grad_norm)
_train = trainer.apply_gradients()
---------------------
# Runnder������Ӗ(x��n)���^�̵ąf(xi��)�{(di��o)�ߡ�
runner = Runner(env=env, model=model, nsteps=nsteps,...)
# total_timesteps = 11000000, nbatch = 1024�����ģ�ͅ���(sh��)����nupdates = 10742�Ρ�
nupdates = total_timesteps // nbatch
for update in range(1, nupdates+1) # ����(y��ng)Փ����Algorithm����ѭ�h(hu��n)��
obs, returns, masks, actions, values, ... = runner.run()
# ģ�ͣ������act_model����(zh��)��nsteps������8���h(hu��n)��������1024����ԓѭ�h(hu��n)����(y��ng)Փ����Algorithm�ĵ�2,3�С�
for _ in range(self.nsteps):
# ��(zh��)��ģ�ͣ�ͨ�^���ԾW(w��ng)�j(lu��)��������
actions, values, self.states, ... = self.model.step(self.obs, self.status, ...)
# ͨ�^֮ǰ��(chu��ng)���ĭh(hu��n)����(zh��)�Є������õ�observation��reward����Ϣ��
self.obs[:], rewards, self.dones, infos = self.env.step(actions)
# ����h(hu��n)����(zh��)�з��ص�observation, action, values����Ϣ������mb_xxx�д�����������Ҫ�Á�W(xu��)��(x��)����(sh��)�á�
mb_obs = np.asarray(mb_obs, dtype=self.obs.dtype)
mb_rewards = np.asarray(mb_rewards, dtype=np.float32)
mb_actions = np.asarray(mb_actions)
...
# ��ӋAdvantage������(y��ng)������Algorithm�ĵ�4�С�
for t in reversed(range(self.nsteps)):
# Փ���й�ʽ(12)��
delta = mb_rewards[t] + self.gamma * nextvalues * nextnonterminal - mb_values[t]
# Փ���й�ʽ(11)��
mb_advs[t] = lastgaelam = delta + self.gamma * self.lam * nextnonterminal * lastgaelam
mb_returns = mb_advs + mb_values # Return = Advantage + Value
return (*map(sf01, (mb_obs, mb_returns, mb_dones, mb_actions, mb_values, mb_neglogpacs)), mb_states, epinfos)
epinfobuf.extend(epinfos) # Gym�з��ص�info��
# Փ����Algorithm 1��6�С�
if states is None: # nonrecurrent version
inds = np.arange(nbatch)
for _ in range(noptepochs): # epoch��4
np.random.shuffle(inds)
# ����actor��ÿ���\��128������ˆ�batch��1024����1024���ַ֞�4��minibatch��
# ��ˆδ�Ӗ(x��n)����batch size��256(nbatch_train)��
for start in range(0, nbatch, nbatch_train): # [0, 256, 512, 768]
end = start + nbatch_train
mbinds = inds[start:end]
slices = (arr[mbinds] for arr in (obs, ...))
# ��ǰ��õ���batchӖ(x��n)����(sh��)��(j��)���酢��(sh��)���{(di��o)��ģ�͵�train()����(sh��)�M�Ѕ���(sh��)�W(xu��)��(x��)��
mblossvals.append(model.train(lrnow, cliprangenow, *slices))
# Advantage = Return - Value
advs = returns - values
# Normalization
advs = (advs - advs.mean()) / (advs.std() + 1e-8)
# cliprange���S�����µIJ���(sh��)�f�p�ġ����һ����fӖ(x��n)��Խ������Խ�Ք���ÿһ���IJҲ��Խ��ԽС��
# neglogpacs��values����nbatch_train�S��������shape��(256, )��
td_map = {train_mode.X:obs, A:actions, ADV:advs, R:returns, LR:lr,
CLIPRANGE:cliprange, OLDNEGLOGPAC:neglogpacs, OLDVPRED:values}
return sess.run([pg_loss, vf_loss, entropy, approxkl, clipfrac, _train], td_map)
else:
...
# ÿ�^ָ���g����ӡ���
���(sh��)��
if update % log_interval == 0 or update == 1:
ev = explained_variance(values, returns)
logger.logkv("serial_timesteps", update*nsteps)
logger.logkv("nupdates", update)
...
# �M��l���r����ģ�͡�
if save_interval and (update % save_interval == 0 or update == 1) and logger.get_dir():
...
model.save(savepath)
env.close()
---------------------
import gym
from gym import spaces
import multiprocessing
import joblib
import sys
import os
import numpy as np
import tensorflow as tf
from baselines.ppo2 import ppo2
from baselines.common.cmd_util import make_atari_env, atari_arg_parser
from baselines.common.atari_wrappers import make_atari, wrap_deepmind
from baselines.ppo2.policies import CnnPolicy
from baselines.common.vec_env.vec_frame_stack import VecFrameStack
def main(argv):
ncpu = multiprocessing.cpu_count()
config = tf.ConfigProto(allow_soft_placement=True,
intra_op_parallelism_threads=ncpu,
inter_op_parallelism_threads=ncpu)
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
env_id = "BreakoutNoFrameskip-v4"
seed = 0
nenvs = 1
nstack = 4
env = wrap_deepmind(make_atari(env_id))
ob_space = env.observation_space
ac_space = env.action_space
wos = env.observation_space
low = np.repeat(wos.low, nstack, axis=-1)
high = np.repeat(wos.high, nstack, axis=-1)
stackedobs = np.zeros((nenvs,)+low.shape, low.dtype)
observation_space = spaces.Box(low=low, high=high, dtype=env.observation_space.dtype)
vec_ob_space = observation_space
act_model = CnnPolicy(sess, vec_ob_space, ac_space, nenvs, 1, reuse=False)
with tf.variable_scope('model'):
params = tf.trainable_variables()
#load_path = '/tmp/openai-2018-05-27-15-06-16-102537/checkpoints/00030'
load_path = argv[0]
loaded_params = joblib.load(load_path)
restores = []
for p, loaded_p in zip(params, loaded_params):
restores.append(p.assign(loaded_p))
sess.run(restores)
print("model " + load_path + " loaded")
obs = env.reset()
done = False
for _ in range(1000):
env.render()
obs = np.expand_dims(obs, axis=0)
stackedobs = np.roll(stackedobs, shift=-1, axis=-1)
stackedobs[..., -obs.shape[-1]:] = obs
actions, values, states, neglogpacs = act_model.step(stackedobs)
print("%d, action=%d" % (_, actions[0]))
obs, reward, done, info = env.step(actions[0])
if done:
print("done")
obs = env.reset()
stackedobs.fill(0)
sess.close()
if __name__ == '__main__':
if (len(sys.argv)) != 2:
sys.exit("Usage: %s ckpt_path" % sys.argv[0])
if not os.path.exists(sys.argv[1]):
sys.exit("ckpt file %s not found" % sys.argv[1])
main(sys.argv[1:])
---------------------
(li��n)ϵ��highspeedlogic
QQ ��1224848052
�ţ�HuangL1121
�]�䣺1224848052@qq.com
�W(w��ng)վ��http://www.mat7lab.com/
�W(w��ng)վ��http://www.hslogic.com/
�Œ�һ�ߣ�