����������
����ȌW�����F����Ę�R�e���g���������˿����ԡ��@�����֮ǰ�ęC���W�����g�У��y�ԏĈDƬ��ȡ�����m������ֵ��݆�����ɫ���۾�����˶����ף����S����o���⾀���Ĕz�Ƕȡ���ɫ�����顢���y�������ȵȵIJ�ͬ��ͬһ���˵������Ƭ����Ƭ���،����ϲ�e�ܴ{�茣�҂��Ľ���cԇ�e�y��ȡ���ʴ_���^�ߵ�����ֵ����ȻҲ�]�����@Щ����ֵ�Mһ�������ȌW�������������Ӗ���㷨�����{���������أ������һ���ʴ_���^�ߵ�f(x)�������o��һ����Ƭ�t���ԫ@ȡ������ֵ���M���ٚw������йP��ԇ�D��ͨ���Z��̽ӑ��Ę�R�e���g�����ȸ�����Ę�R�e���g������̽ӑ��ȌW����Ч��ԭ���Լ��ݶ��½���ʲô����Ӗ�������m�ę������������������CNN���e�W�j����Ę�R�e��
һ����Ę�R�e���g����
��Ę�R�e���g��������Ę�z�y����Ę�R�e�ɂ��h���M�ɡ�
֮����Ҫ����Ę�z�y�������Ǟ��˙z�y����Ƭ���Ƿ�����Ę������Ҫ���ǰ���Ƭ����Ę�o�P�IJ��քh������t������Ƭ�����ض����of(x)�R�e�����϶��Ͳ������ˡ���Ę�z�y��һ����ʹ����ȌW�����g������@��ļ��gҪ��������һЩ��ֻ��Ҫ֪���Л]����Ę�Լ���Ę����Ƭ�еĴ���λ�ü��ɡ�һ���҂����]ʹ��opencv��dlib���_Դ�����Ę�z�y���ܣ����ڌ��ҽ��Ă��y����ֵ����Ӌ�����ُĶ��ٶȸ��죩��Ҳ����ʹ�û�����ȌW�����F�ļ��g��mtcnn�����W�j�^���^���r�\������Ķ���һЩ����
����Ę�z�y�h���У��҂���Ҫ�Pע�z�y�ʡ�©�z�ʡ��`�z������ָ�ˣ����У�
�z�y�ʣ�������Ę���ұ��z�y���ĈD�������д�����Ę�D���еı�����
©�z�ʣ�������Ę���Ǜ]�Йz�y���ĈD�������д�����Ę�D���еı�����
�`�z�ʣ���������Ę���Ǚz�y��������Ę�ĈD�������в�������Ę�D���еı�����
��Ȼ���z�y�ٶ�Ҳ����Ҫ�����IJ�����Ę�z�y���Mһ��������
����Ę�R�e�h�����䑪�È���һ��֞�1:1��1:N��
1��1�����Д��ɏ���Ƭ�Ƿ��ͬһ���ˣ�ͨ�����������Cƥ���ϣ����������C�c���rץ�����Ƿ��ͬһ���ˣ���Ҋ�ڸ��N�I�I�d�Լ������B��1:N�����е�ע�ԭh������1:N���È������t�����Ȉ���ע�ԭh�����o��N��ݔ�������Ę��Ƭ�Լ���ID���R���و����R�e�h�����o����Ę��Ƭ����ݔ�룬ݔ���t��ע�ԭh���е�ij��ID���R���߲���ע����Ƭ�С���Ҋ���ĸ��ʽǶ��ρ�����ǰ�����������S�࣬�������C����ͨ���c������Ƭ����g���r�g����������ͨ���҂��O�������ƶ��ֵ���DZ��^�͵ģ��Դ˫@�ñ��^�õ�ͨ�^�ʣ������Ըߵ��`�R�e�ʡ�
������1��N���S��N��׃���`�R�e�ʕ����ߣ��R�e�r�gҲ�����L���������ƶ��ֵͨ�����O�����^�ߣ�ͨ�^�ʕ��½����@�ﺆ�ν��������Ďׂ����~���`�R�e�ʾ�����Ƭ�䌍��A�ąs�R�e��B�ı��ʣ�ͨ�^�ʾ�����Ƭ�_����A�ģ�������ÿ5��A����Ƭ�����R�e��4����A��ͨ�^�ʾ͞�80%�����ƶ��ֵ����錦����ֵ�M�з���Ǹ����О飬����ݔ��ăɏ���Ƭ�䌍��ͬһ���ļ�����t�κɏ���Ƭ֮�g����һ�����ƶȣ��O�������ƶ��ֵ��Ψ�Ѓɏ���Ƭ�����ƶȳ��^�ֵ�����J����ͬһ���ˡ����ԣ��μ����u�rij����Ę�R�e�㷨�Ĝʴ_�ʛ]�����x���҂�����ҪŪ��������`�R�e��С��ij��ֵ�r������0.1%����ͨ�^�ʡ�����1:1߀��1:N����Ӽ��g����ͬ�ģ�ֻ���y�Ȳ�ͬ���ѡ�
ȡ����Ę����ֵ�����y�ģ���ô��ȌW�������ȡ����ֵ�ģ�
�ٶ��҂��o������Ę��Ƭ��100*100���ش�С������ÿ��������RGB����ͨ����ÿ������ͨ����0-255�������ֹ���ʾ���t����3��100*100�ľ��Ӌ3�f���ֹ�����ݔ�딵������ȌW�����H�Ͼ�������һ�����ƺ������������ݔ��ֵ�D����������������������ֵ����ô������ֵ������һ�����ֆ��Ȼ���У�һ�����֣����߽И������ǟo����Ч��ʾ�������ġ�ͨ���҂��ö�����ֵ�M�ɵ�������ʾ����ֵ�������ľS�ȼ����еĔ�ֵ���������������ľS�Ȳ���Խ��Խ�ã�google��facenet�Ŀ����Ҋhttps://arxiv.org/abs/1503.03832Փ�ģ����^�Ĝyԇ�Y���@ʾ��128����ֵ�M�ɵ����������Y����ã����D��ʾ��
��ô���F�چ��}���D������ô��3*100*100�ľ���D����128�S�����������@�������܉�ʴ_�ą^�ֳ���ͬ����Ę��
�ٶ���Ƭ��x������ֵ��y��Ҳ�����f����һ������f(x)=y�����������ҳ���Ƭ����Ę����ֵ���F���҂���һ��f*(x)���ƺ������������Ѕ���w�����߽Й���w�������O�ã����猑��f*(x;w)������Ӗ����x����id���Ry���O��ʼ����p1����ôÿ��f*(x;w)�õ���y`�c���H���Ry��ȣ������_�tͨ�^�����e�`�t�m���{������w������܉����_���{���Å���w��f*(x;w)�͕��c�����е�f(x)�������ӽ����҂��ͫ@���˸��������ߜʴ_�ʵ�f*(x;w)�������@һ�^�̽����O���W���µ�Ӗ������Ӌ��f*(x;w)ֵ���^������������ĺ����\�㣬�҂��Q��ǰ���\�㣬��Ӗ���^���б��^y`�c���H���Ridֵy�Y�����{������p���^�̄t�Ƿ��^���ģ��Q�鷴�������
�����҂����f��x�녢������һ����Ƭ����Ƭ���Ќ������⾀���ǶȵȌ��µIJ�̫���������|�����}��Ҳ�б��������ؔ����ن��}�����x�������еĔ���̫�٣����DƬ�dz�������������28*28���ص���Ƭ����ô�lҲ�o���ʴ_�ķֱ�����Ă��ˡ�������Ҋ����Ȼ���ؔ�Խ���R�eҲԽ�ʣ������ؔ�Խ�����µ�Ӌ�㡢��ݔ���惦����ҲԽ���҂���Ҫ�и������ҵ����m���ֵ���D��facenetՓ�ĵĽY�����mȻֻ��һ��֮�ԣ���google�ć�֔�B��ʹ�Ô���Ҳ���Ѕ����rֵ��
������ȌW�����g��ԭ��
����������Ę���D����������ֵ��ꇣ������OӋ��ʲô�ӵĺ���f(x)�D��������ֵ�أ��@�����}�Ĵ���ه�ڷ���}�������Ȳ�Մ����ֵ��������ΰ���Ƭ���ϰ������_�ķ���@���Ҫ��ՄՄ�C���W�����C���W���J����ԏ�����Ӗ�����ӱ��а��㷨�ܺõķ��������ԣ��҂����ҵ�����Ӗ�������OӋ�ó�ʼ����f(x;w)�����ѽ���������Ӗ������x->y���������x�ǵ;S�ġ����εģ�����ֻ�ж��S����ô��ܺ��Σ����D��ʾ��
�ψD�еĶ��S����xֻ�з��κ͈A�ɂ�ey���ܺ÷֣��҂���Ҫ�W���ķ��������ε�f(x,y)=ax+by+c���ܱ�ʾ�����ֱ��������f(x,y)����0�r��ʾ�A�Σ�С��0�r��ʾ���Ρ�
�o���S�C������a,c,b�ij�ʼֵ���҂�ͨ�^Ӗ����������ă�������a,b,c���Ѳ����m��L1��L3�ȷ������uӖ����L2���@�ӵ�L2ȥ�挦�����Ĝyԇ�����Ϳ��ܫ@�ø��õ�Ч����Ȼ������ж���e������Ҫ���l���ֱ�����ֳܷ������D��ʾ��
�@�䌍�ஔ�ڶ��l����������c&&����||������ĽY�����@���r��߀������f1>0 && f2<0 && f3>0�@�ӵķ����������������s��Ԓ�����籾�������������@Ҳ�]�ЅR����һ���@�N�������ķ�ʽ���治�D�ˣ����D��ʾ����ͬ���ɫ��ʾ��ͬ�ķ���˕r��Ӗ��������ȫ�ǷǾ��ԿɷֵĠ�B��
�@���r���҂�����ͨ�^���Ӻ���Ƕ�ķ�������Q������f(x)=f1(f2(x))���@��f2���������ǔ��lֱ������f1��������ͨ�^��ͬ�ę���w�Լ����������c&&����||�ȵȲ������@��ֻ�ЃɌӺ������������Ƕ�Ӕ�Խ�࣬��Խ�ܱ��_�����s�ķ�������@���߾S�������Ў����������҂�����Ƭ���o�Ɇ������@�ӵ�ݔ�롣���^��������ǰѺ���fӋ����ķdz����ֵ���D����[0,1]�@���^С��ֵ���@���S���Ӻ��������ǰ���\�㡢���
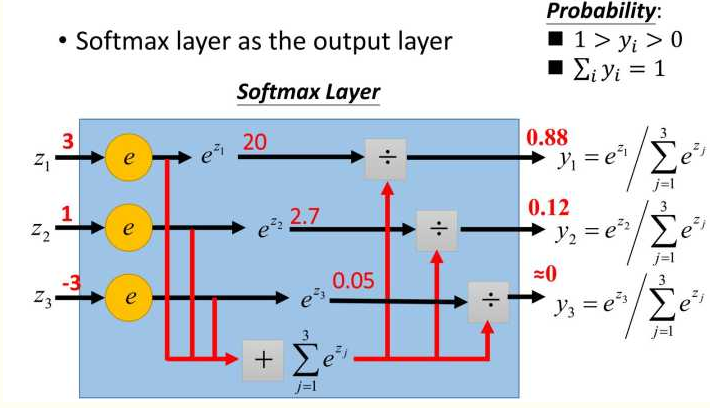
ǰ���\��ֻ�ǰ�ݔ�뽻�of1(x,w1)������Ӌ�����ֵ�ٽ��of2(y1,w2)������������ƣ��ܺ��ξͿ��Եõ���K�ķ��ֵ�����ǣ�����ʼ��w�����䌍�]�ж�����x�����ó��ķ��ֵf*(x)�϶����e�ģ���Ӗ�������҂�֪�����_��ֵy����ô�����҂��䌍��ϣ��y-f*(x)��ֵ��С���@�ӷ��Խ�ʡ��@�䌍׃��������Сֵ�Ć��}����Ȼ��y-f*(x)ֻ��ʾ�⣬�����҂��õ���f*(x)ֻ���䵽��������ϵĸ��ʣ����@�������c�挍�ķ������^�õ���Сֵ���^�̣��҂��Q��pʧ��������ֵ��loss���҂���Ŀ���ǰѓpʧ������ֵloss��С��������Ę�R�e�����У�softmax��һ��Ч�����^�õēpʧ�������҂����ο����������ʹ�õġ�
�����҂���Ӗ����������Ƭ������cat��dog��ship����e��ij��ݔ����Ƭ���^����f(x)=x*W+b��ǰ���\��õ�ԓ��Ƭ�����@3����ĵ÷�ֵ���˕r���@���������Q��÷ֺ��������D��ʾ�����O��߅�P��؈��input image��һ��4�S����[56,231,24,2]����W������һ��4*3�ľ�ꇣ���ô��˺��ټ�������[1.1,3.2,-1.2]�ɵõ���cat�� dog��ship����e�ϵĵ÷֣�
���ψDʾ����Ҋ���mȻݔ����Ƭ��؈�����÷��ό��ڹ��ĵ÷�ֵ437.9��ߣ���������؈�ʹ��߶����أ����y����������҂��ѵ÷�ֵ�D����0-100�İٷֱȸ��ʣ��@�ͷ�������ˡ��@���҂�����ʹ��sigmoid���������D��ʾ��
ϵ��highspeedlogic
QQ ��1224848052
�ţ�HuangL1121
�]�䣺1224848052@qq.com
�Wվ��http://www.mat7lab.com/
�Wվ��http://www.hslogic.com/
�Œ�һ�ߣ�

|