Relu�����(sh��)
Relu����(sh��)��f(x)= max(0,x)
1.sigmoid�ctanh��ͅ^(q��)��Relu����(sh��)��x>0�r��(d��o)��(sh��)һֱ��1����?y��n)��ݶȵ��B�˱��_(d��)ʽ�������Ӽ����(sh��)�Č�(d��o)��(sh��)�Լ����ӵę�(qu��n)�أ�reLU��Q�˼����(sh��)�Č�(d��o)��(sh��)���}�����������ھ����ݶ���ʧ��Ҳ����һ���̶��Ͻ�Q�ݶȱ�ը���Ķ��ӿ�Ӗ(x��n)���ٶȡ�
2.�oՓ���������߀�Ƿ��������Ӌ�����@��С��sigmoid��tanh��
from keras.models import Sequential from keras.layers import Dense, Flatten, Dropout from keras.layers.convolutional import Conv2D, MaxPooling2D from keras.utils.np_utils import to_categorical
import numpy as np
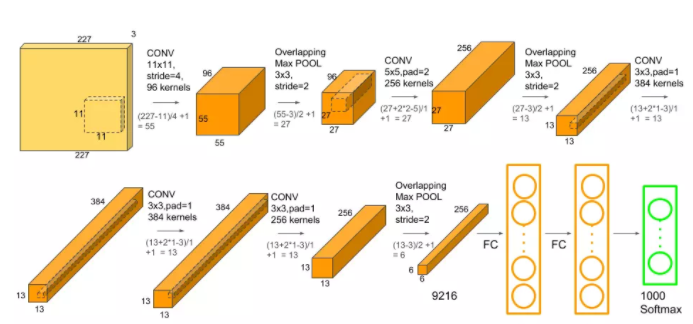
seed = 7 np.random.seed(seed) # ��(chu��ng)��ģ������ model = Sequential() #��һ�Ӿ��e�W(w��ng)�j(lu��)��ʹ��96�����e�ˣ���С��11x11���L��4�� Ҫ��ݔ��ĈDƬ��227x227�� 3��ͨ��������߅�������(sh��)ʹ��relu model.add(Conv2D(96, (11, 11), strides=(1, 1), input_shape=(28, 28, 1), padding='same', activation='relu', kernel_initializer='uniform')) # �ػ��� model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) # �ڶ��Ӽ�߅ʹ��256��5x5�ľ��e�ˣ���߅�������(sh��)��relu model.add(Conv2D(256, (5, 5), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform')) #ʹ�óػ��ӣ����L��2 model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) # �����Ӿ��e����С��3x3�ľ��e��ʹ��384�� model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform')) # ���ČӾ��e,ͬ������ model.add(Conv2D(384, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform')) # ����Ӿ��eʹ�õľ��e�˞�256��������ͬ�� model.add(Conv2D(256, (3, 3), strides=(1, 1), padding='same', activation='relu', kernel_initializer='uniform')) model.add(MaxPooling2D(pool_size=(3, 3), strides=(2, 2))) model.add(Flatten()) model.add(Dense(4096, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(4096, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(10, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy']) model.summary() ������Դ��(https://blog.csdn.net/qq_41559533/article/details/83718778 )
(li��n)ϵ��highspeedlogic
QQ ��1224848052
�ţ�HuangL1121
�]�䣺1224848052@qq.com
�W(w��ng)վ��http://www.mat7lab.com/
�W(w��ng)վ��http://www.hslogic.com/
�Œ�һ�ߣ�